- Computer Architecture and Implementation

Содержание
- 2. Instruction-Level Parallelism Relevant Book Reading (HP3): Dynamic Scheduling (in hardware): Appendix A & Chapter 3 Compiler
- 3. Hardware Schemes for ILP Why do it in hardware at run time? Works when can’t know
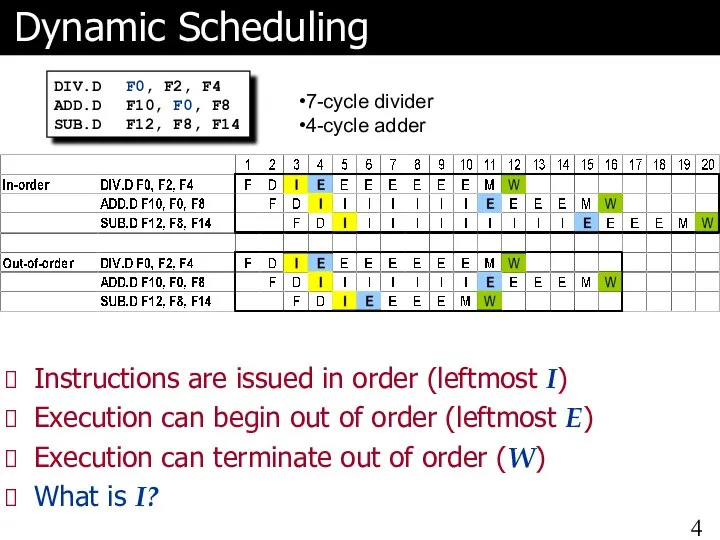
- 4. Dynamic Scheduling DIV.D F0, F2, F4 ADD.D F10, F0, F8 SUB.D F12, F8, F14 7-cycle divider
- 5. Explanation of I To be able to execute the SUB.D instruction A function unit must be
- 6. Out-of-order Execution and Renaming WAW hazard on register F10: prevents out-of-order execution on machine like CDC
- 7. Memory Consistency Memory consistency refers to the order of main memory accesses as compared to the
- 8. Four Possibilities for Load/Store Motion Load-Load LW R1, (R2) LW R3, (R4) Load-Load can always be
- 9. More on Load Bypassing and Forwarding Either transformation can be performed at compile time if the
- 10. Load Bypassing in Hardware Requires two separate queues for LOADs and STOREs Every LOAD has to
- 11. Example of Load Bypassing Memory access takes four cycles Actions at various points in time End
- 13. Скачать презентацию
Instruction-Level Parallelism
Relevant Book Reading (HP3):
Dynamic Scheduling (in hardware): Appendix A
Instruction-Level Parallelism
Relevant Book Reading (HP3):
Dynamic Scheduling (in hardware): Appendix A

Hardware Schemes for ILP
Why do it in hardware at run time?
Works
Hardware Schemes for ILP
Why do it in hardware at run time?
Works
Dynamic Scheduling
DIV.D F0, F2, F4
ADD.D F10, F0, F8
SUB.D F12, F8, F14
7-cycle divider
4-cycle adder
Instructions are
Dynamic Scheduling
DIV.D F0, F2, F4
ADD.D F10, F0, F8
SUB.D F12, F8, F14
7-cycle divider
4-cycle adder
Instructions are

Explanation of I
To be able to execute the SUB.D instruction
A function
Explanation of I
To be able to execute the SUB.D instruction
A function

Out-of-order Execution and Renaming
WAW hazard on register F10: prevents out-of-order execution
Out-of-order Execution and Renaming
WAW hazard on register F10: prevents out-of-order execution

Memory Consistency
Memory consistency refers to the order of main memory accesses
Memory Consistency
Memory consistency refers to the order of main memory accesses
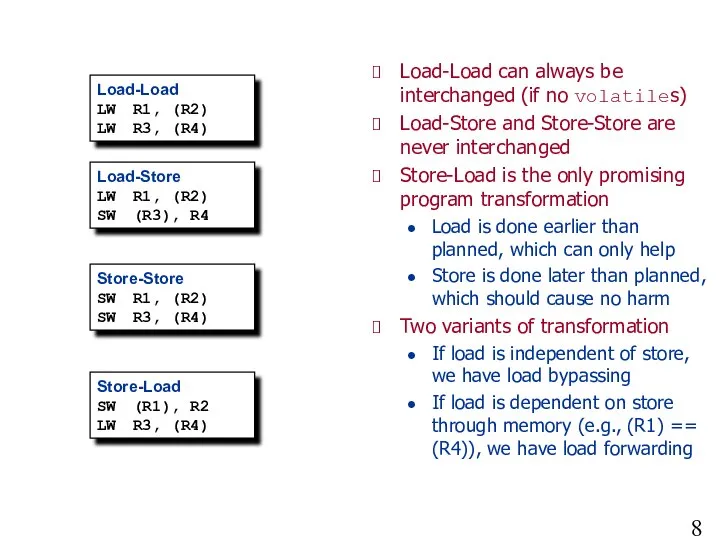
Four Possibilities for Load/Store Motion
Load-Load
LW R1, (R2)
LW R3, (R4)
Load-Load can always be interchanged
Four Possibilities for Load/Store Motion
Load-Load
LW R1, (R2)
LW R3, (R4)
Load-Load can always be interchanged
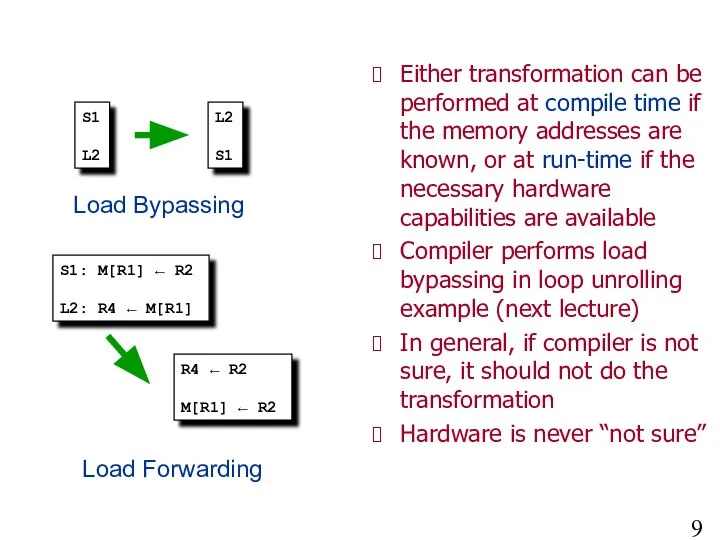
More on Load Bypassing and Forwarding
Either transformation can be performed at
More on Load Bypassing and Forwarding
Either transformation can be performed at

Load Bypassing in Hardware
Requires two separate queues for LOADs and STOREs
Every
Load Bypassing in Hardware
Requires two separate queues for LOADs and STOREs
Every
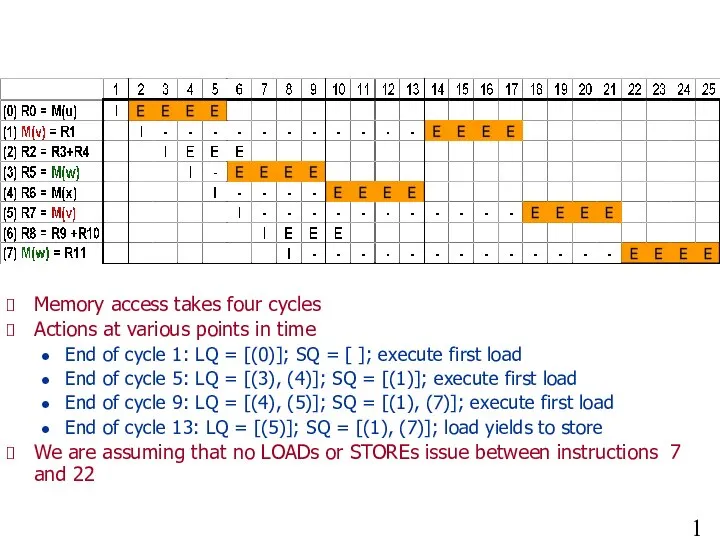
Example of Load Bypassing
Memory access takes four cycles
Actions at various points
Example of Load Bypassing
Memory access takes four cycles
Actions at various points
 История отношений России и Британии
История отношений России и Британии Улуттук кийимдер жана жасалгалар
Улуттук кийимдер жана жасалгалар Морально-этические принципы работы юриста уголовно-правовой специализации
Морально-этические принципы работы юриста уголовно-правовой специализации ТЕМА 1.2. ИСТОЧНИКИ ГРАЖДАНСКОГО ПРАВА _
ТЕМА 1.2. ИСТОЧНИКИ ГРАЖДАНСКОГО ПРАВА _ Дифракция световых волн 2
Дифракция световых волн 2 Инструкция по ремонту рукояти
Инструкция по ремонту рукояти Технологический процесс технического обслуживания и ремонта системы питания автомобиля ГАЗ- 3307
Технологический процесс технического обслуживания и ремонта системы питания автомобиля ГАЗ- 3307 Тема: «Кружевные узоры» Украшения и фантазия Составила: Газизова З.А., учитель Нововасюга
Тема: «Кружевные узоры» Украшения и фантазия Составила: Газизова З.А., учитель Нововасюга ФИЗИОЛОГИЯ СИНАПСОВ. ФИЗИОЛОГИЯ НЕЙРОНА. ФИЗИОЛОГИЯ ЖЕЛЕЗ
ФИЗИОЛОГИЯ СИНАПСОВ. ФИЗИОЛОГИЯ НЕЙРОНА. ФИЗИОЛОГИЯ ЖЕЛЕЗ Рекурсия и сложность
Рекурсия и сложность  Лечение бронхиальной астмы
Лечение бронхиальной астмы Теорія електричних та електронних кіл
Теорія електричних та електронних кіл Допиши предложения - презентация для начальной школы
Допиши предложения - презентация для начальной школы Благоустройство общественного пространства по адресу: Ростовская область, станица Егорлыкская. «Город на земле»
Благоустройство общественного пространства по адресу: Ростовская область, станица Егорлыкская. «Город на земле» Есть ли разум во Вселенной
Есть ли разум во Вселенной Горные экосистемы
Горные экосистемы  Современные методы управления
Современные методы управления Дресс-код в компании
Дресс-код в компании Аттестационная работа. Образовательная программа внеурочной деятельности спортивно-оздоровительного кружка «Туризм»
Аттестационная работа. Образовательная программа внеурочной деятельности спортивно-оздоровительного кружка «Туризм» Физико-механические свойства арматуры
Физико-механические свойства арматуры Самовсасывающие устройства применяемые на технических средствах службы горючего
Самовсасывающие устройства применяемые на технических средствах службы горючего Презентация к уроку МХК в 6 классе по теме «Рождение христианской художественной образности. Библия как основная книга христианс
Презентация к уроку МХК в 6 классе по теме «Рождение христианской художественной образности. Библия как основная книга христианс Сущность и виды предпринимательской деятельности
Сущность и виды предпринимательской деятельности Решение дробных рациональных уравнений Алгебра 8 класс
Решение дробных рациональных уравнений Алгебра 8 класс Умный ночник
Умный ночник Международный конкурс социальных проектов с применением цифровых технологий «Social Idea». МТС
Международный конкурс социальных проектов с применением цифровых технологий «Social Idea». МТС Молоко и молочные товары
Молоко и молочные товары Dziesięć Bożych przykazań
Dziesięć Bożych przykazań