- Серверы суперкомпьютеры

Содержание
- 2. §1 Архитектуры параллельных компьютеров 1. За счёт чего выросла производительность
- 3. конвейер прогноз ветвлений и т. д. параллелизм много процессоров, банков памяти, УВВ внутри процессора: много конвейеров,
- 4. Основная проблема – взаимодействие паралл. работающих устройств проц-ы память УВВ
- 5. 2. Топология диаметр – расстояние (в этапах) между наиболее удалёнными узлами
- 6. размерность – число цепочек, пересекающихся в каждом узле 0: - звезда - полное межсоединение - толстое
- 7. 1: - кольцо - решётка - 2М тор 2:
- 8. 3: - куб 4: 4М куб 3М тор
- 9. Чем больше размерность, тем меньше задержки, поскольку отношение диаметра к числу узлов уменьшается
- 10. Connection Machine 2
- 11. 3. Маршрутизация от источника: источник определяет весь путь заранее и прикрепляет к пакету список номеров портов
- 12. пространственная: по осям на нужное число узлов не создаёт тупиковых ситуаций
- 13. 4. Организация памяти совместная: единое физическое адресное пространство распределённая: физически раздельное, логически единое
- 14. Обмен данными при распред. организации: проц. определяет, у кого есть нужные ему данные посылает запрос блокируется
- 15. Совместную память легко программировать, но трудно сделать (гигабайты) Распределённую – наоборот Комбинации
- 16. §2 Расширяемый связный интерфейс – РСИ 1. Назначение Scalable Coherent Interface – SCI суперкомпьютеры САУ (реального
- 17. Примеры: управление ядерным реактором крылатая ракета танк-робот комплекс ПВО прогноз погоды, землетрясений научные расчёты
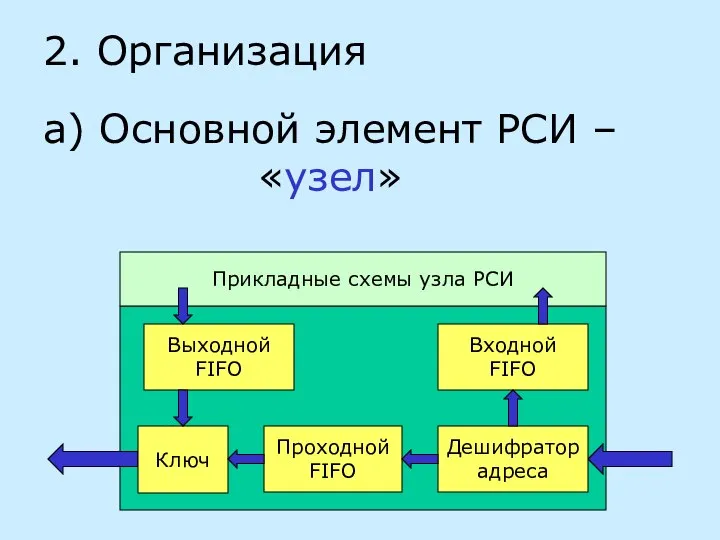
- 18. 2. Организация а) Основной элемент РСИ – «узел» Ключ Проходной FIFO Дешифратор адреса Выходной FIFO Входной
- 19. Пакет поступает на дешифратор адреса Если адрес в пакете = адресу узла, то направляем пакет во
- 20. Иначе пакет попадает в проходной FIFO и, если ключ открыт, выходит из узла ключ закрыт, когда
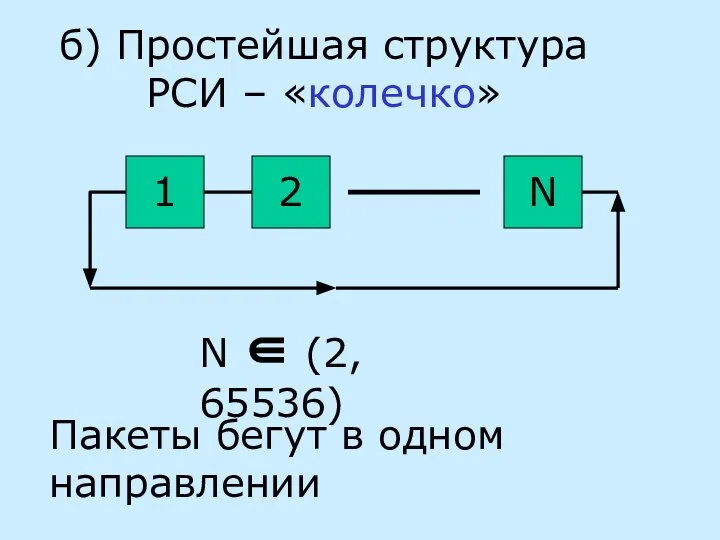
- 21. б) Простейшая структура РСИ – «колечко» 1 2 N N ∈ (2, 65536) Пакеты бегут в
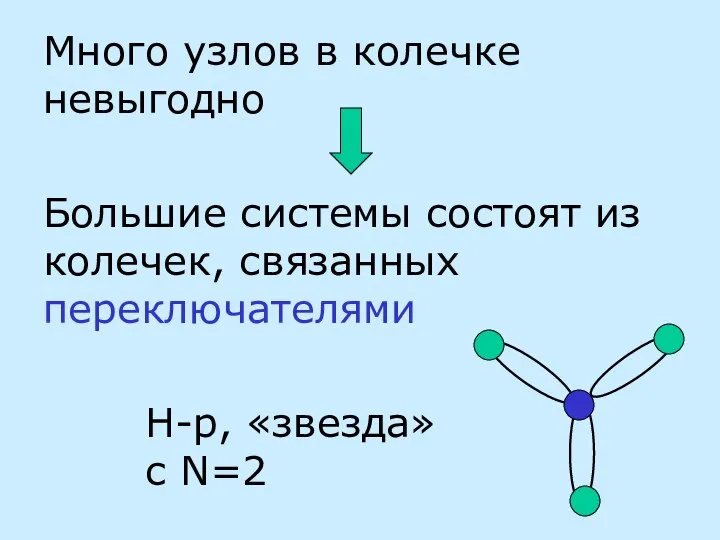
- 22. Много узлов в колечке невыгодно Большие системы состоят из колечек, связанных переключателями Н-р, «звезда» c N=2
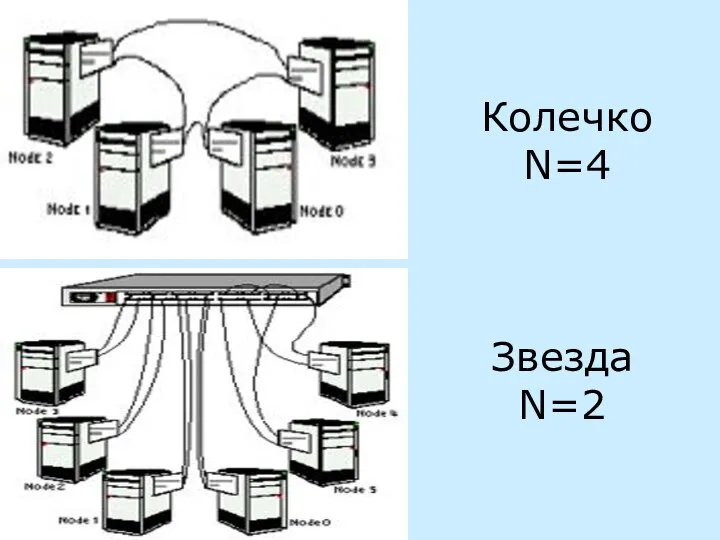
- 23. Колечко N=4 Звезда N=2
- 24. в) Двойной узел Узел+ Прикладные схемы Узел- вх- вых- вх+ вых+
- 25. Из двойных узлов компонуют резервированные колечки «Гигаринг»
- 26. В случае разрыва одного колечка, работает оставшееся Н-р:
- 27. Если разрушены один-два узла, то колечко просто укорачивается Живучесть системы
- 28. г) Дворник колечка удаляет повреждённые пакеты управляет синхронизацией узлов полностью очищает колечко при крупных сбоях
- 29. д) Инициализация системы при включении питания каждый узел запускает свой тактовый генератор в каждом колечке избирается
- 30. программа высшего уровня активизирует переключатели между колечками затем присваивает каждому узлу уникальный адрес
- 31. 3. InfiniBand Наследник РСИ: обработка пакетов в узле менеджеры подсетей – дворники менеджер системы Но колечки
- 32. Схема кодирования 8В/10В: 8 разрядов данных + 2 разряда для синхронизации Распараллеливание на уровне байтов
- 33. Пропускная способность
- 34. 1x-1x 4x-1x 4x: 16 жил Медные кабели до 17 м
- 35. Сетевая карта на 40 Гбит/с Для PCI Express 2.0: (5 млрд. транзакций/c) ⇒ дуплексный обмен в
- 37. Скачать презентацию

§1 Архитектуры параллельных компьютеров
1. За счёт чего выросла производительность
§1 Архитектуры параллельных компьютеров
1. За счёт чего выросла производительность

конвейер
прогноз ветвлений и т. д.
параллелизм
много процессоров, банков
конвейер
прогноз ветвлений и т. д.
параллелизм
много процессоров, банков
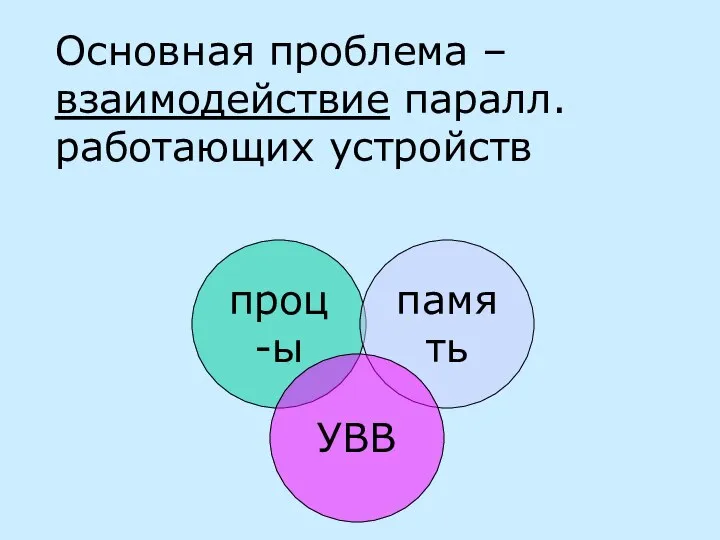
Основная проблема – взаимодействие паралл. работающих устройств
проц-ы
память
УВВ
Основная проблема – взаимодействие паралл. работающих устройств
проц-ы
память
УВВ
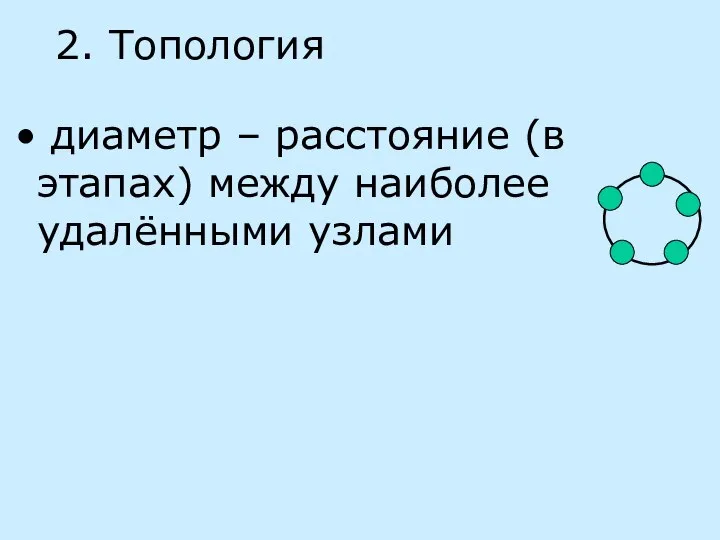
2. Топология
диаметр – расстояние (в этапах) между наиболее удалёнными узлами
2. Топология
диаметр – расстояние (в этапах) между наиболее удалёнными узлами
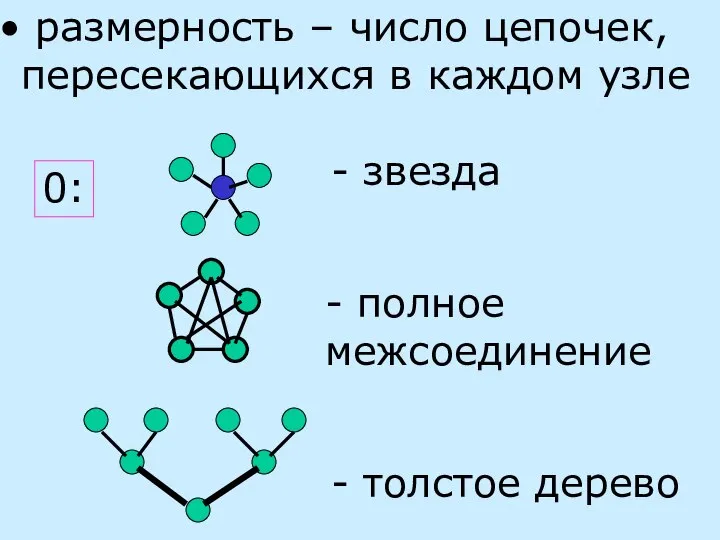
размерность – число цепочек, пересекающихся в каждом узле
0:
- звезда
-
размерность – число цепочек, пересекающихся в каждом узле
0:
- звезда
-
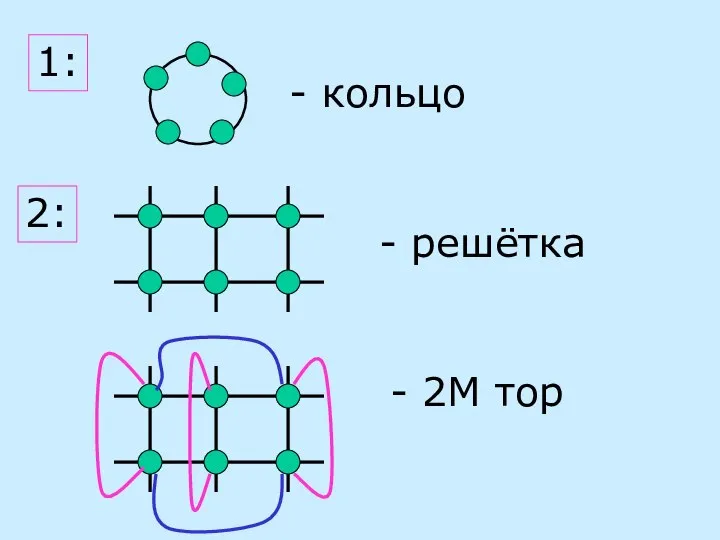
1:
- кольцо
- решётка
- 2М тор
2:
1:
- кольцо
- решётка
- 2М тор
2:
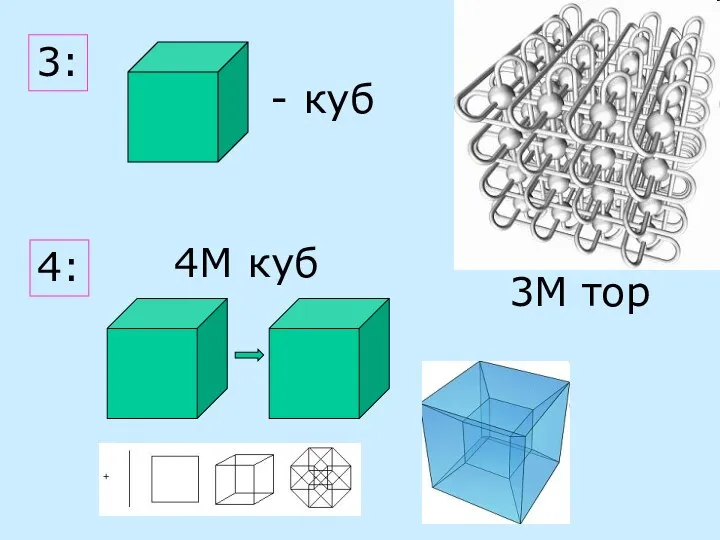
3:
- куб
4:
4М куб
3М тор
3:
- куб
4:
4М куб
3М тор

Чем больше размерность, тем меньше задержки, поскольку отношение диаметра к числу
Чем больше размерность, тем меньше задержки, поскольку отношение диаметра к числу

Connection Machine 2
Connection Machine 2

3. Маршрутизация
от источника: источник определяет весь путь заранее и прикрепляет
3. Маршрутизация
от источника: источник определяет весь путь заранее и прикрепляет
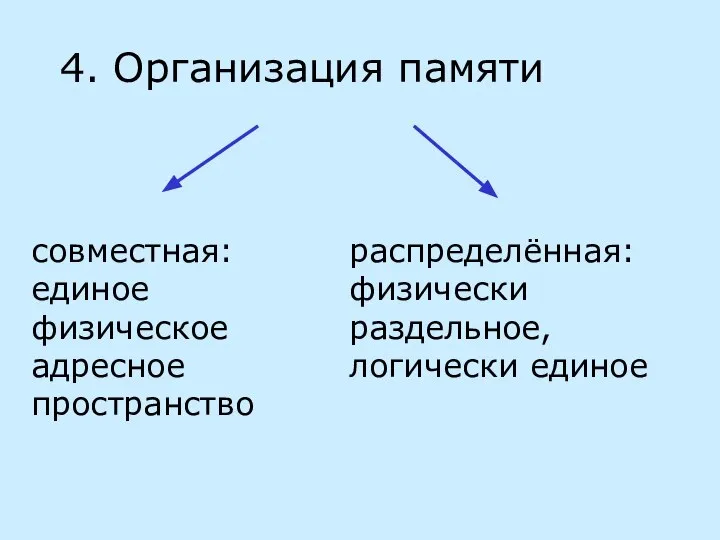
пространственная: по осям на нужное число узлов
не создаёт тупиковых ситуаций
пространственная: по осям на нужное число узлов
не создаёт тупиковых ситуаций
4. Организация памяти
совместная: единое физическое адресное пространство
распределённая: физически раздельное, логически единое
4. Организация памяти
совместная: единое физическое адресное пространство
распределённая: физически раздельное, логически единое

Обмен данными при распред. организации:
проц. определяет, у кого есть нужные
Обмен данными при распред. организации:
проц. определяет, у кого есть нужные
Совместную память легко программировать, но трудно сделать (гигабайты)
Распределённую – наоборот
Комбинации
Совместную память легко программировать, но трудно сделать (гигабайты)
Распределённую – наоборот
Комбинации

§2 Расширяемый связный интерфейс – РСИ
1. Назначение
Scalable Coherent Interface –
§2 Расширяемый связный интерфейс – РСИ
1. Назначение
Scalable Coherent Interface –

Примеры:
управление ядерным реактором
крылатая ракета
танк-робот
комплекс ПВО
прогноз погоды,
Примеры:
управление ядерным реактором
крылатая ракета
танк-робот
комплекс ПВО
прогноз погоды,
2. Организация
а) Основной элемент РСИ – «узел»
Ключ
Проходной FIFO
Дешифратор адреса
Выходной FIFO
Входной FIFO
Прикладные
2. Организация
а) Основной элемент РСИ – «узел»
Ключ
Проходной FIFO
Дешифратор адреса
Выходной FIFO
Входной FIFO
Прикладные

Пакет поступает на дешифратор адреса
Если адрес в пакете =
Пакет поступает на дешифратор адреса
Если адрес в пакете =

Иначе пакет попадает в проходной FIFO и, если ключ открыт,
Иначе пакет попадает в проходной FIFO и, если ключ открыт,
б) Простейшая структура РСИ – «колечко»
1
2
N
N ∈ (2, 65536)
Пакеты бегут в
б) Простейшая структура РСИ – «колечко»
1
2
N
N ∈ (2, 65536)
Пакеты бегут в
Много узлов в колечке невыгодно
Большие системы состоят из колечек, связанных переключателями
Н-р,
Много узлов в колечке невыгодно
Большие системы состоят из колечек, связанных переключателями
Н-р,
Колечко N=4
Звезда N=2
Колечко N=4
Звезда N=2
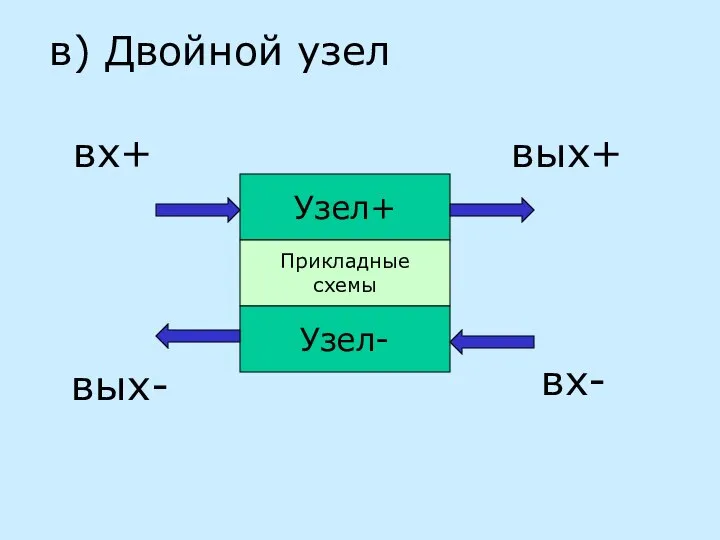
в) Двойной узел
Узел+
Прикладные схемы
Узел-
вх-
вых-
вх+
вых+
в) Двойной узел
Узел+
Прикладные схемы
Узел-
вх-
вых-
вх+
вых+
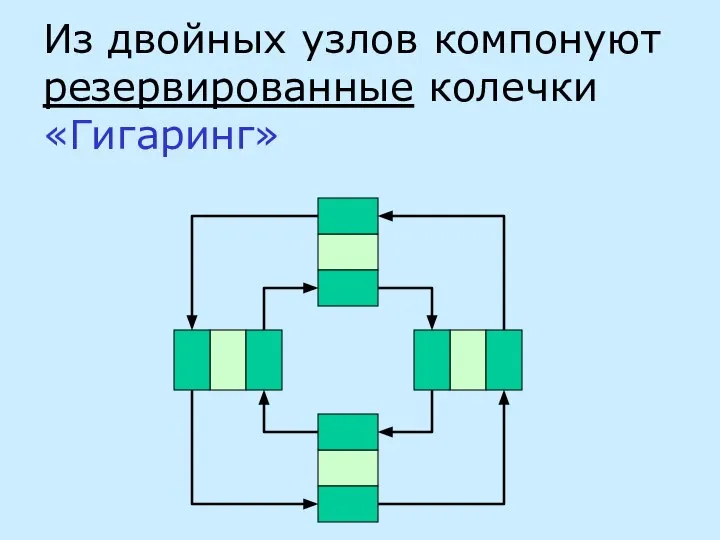
Из двойных узлов компонуют резервированные колечки «Гигаринг»
Из двойных узлов компонуют резервированные колечки «Гигаринг»
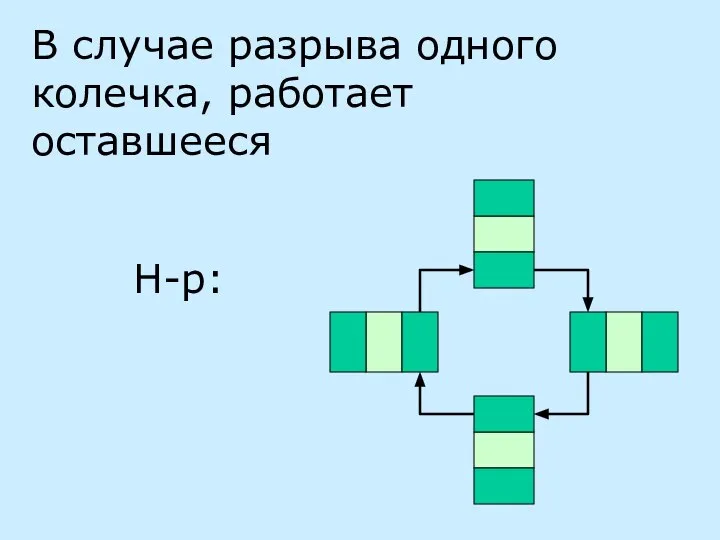
В случае разрыва одного колечка, работает оставшееся
Н-р:
В случае разрыва одного колечка, работает оставшееся
Н-р:
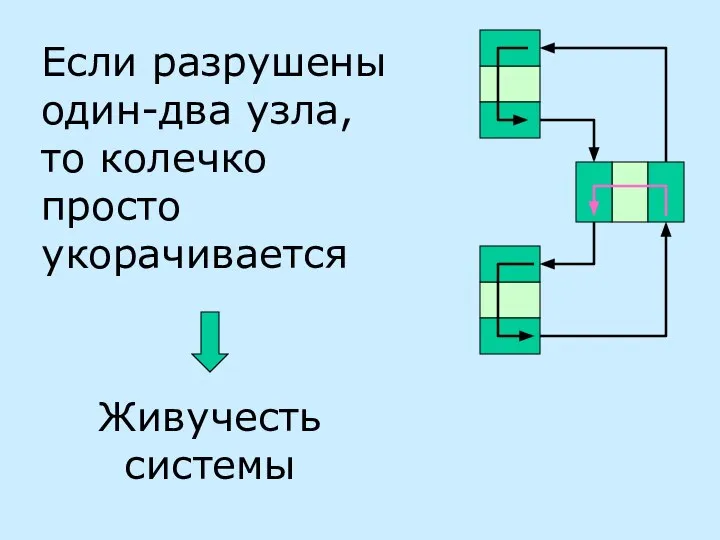
Если разрушены один-два узла, то колечко просто укорачивается
Живучесть системы
Если разрушены один-два узла, то колечко просто укорачивается
Живучесть системы

г) Дворник колечка
удаляет повреждённые пакеты
управляет синхронизацией узлов
полностью очищает
г) Дворник колечка
удаляет повреждённые пакеты
управляет синхронизацией узлов
полностью очищает

д) Инициализация системы
при включении питания каждый узел запускает свой тактовый
д) Инициализация системы
при включении питания каждый узел запускает свой тактовый

программа высшего уровня активизирует переключатели между колечками
затем присваивает каждому
программа высшего уровня активизирует переключатели между колечками
затем присваивает каждому

3. InfiniBand
Наследник РСИ:
обработка пакетов в узле
менеджеры подсетей –
3. InfiniBand
Наследник РСИ:
обработка пакетов в узле
менеджеры подсетей –

Схема кодирования 8В/10В: 8 разрядов данных + 2 разряда для синхронизации
Схема кодирования 8В/10В: 8 разрядов данных + 2 разряда для синхронизации
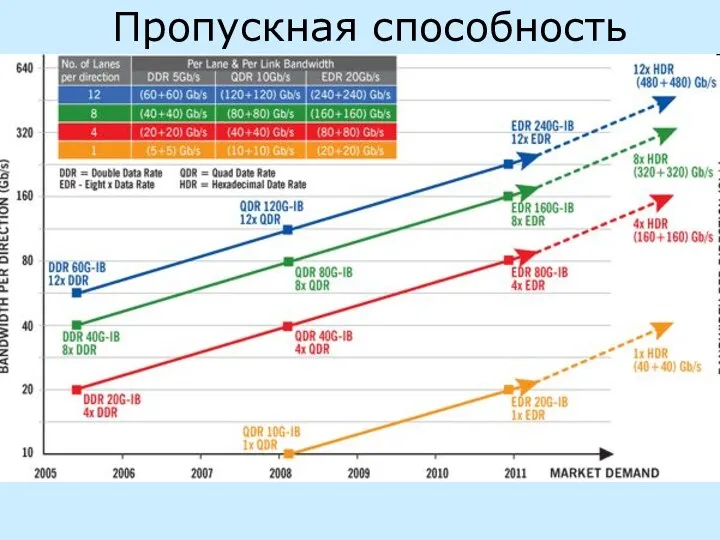
Пропускная способность
Пропускная способность
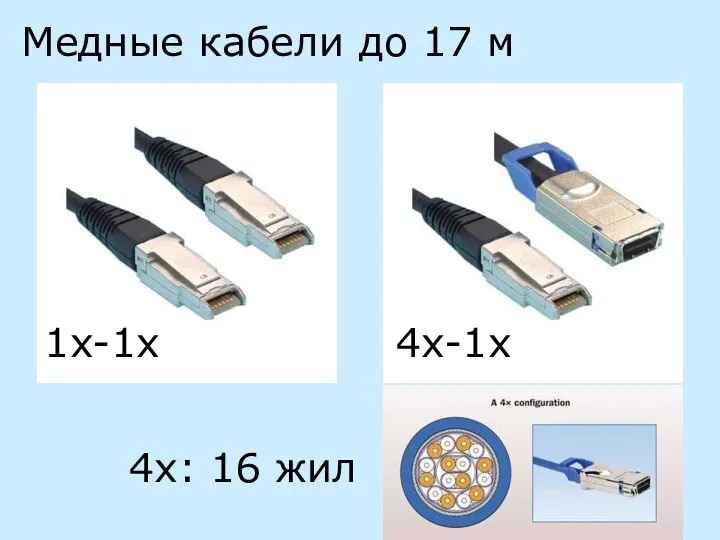
1x-1x
4x-1x
4x: 16 жил
Медные кабели до 17 м
1x-1x
4x-1x
4x: 16 жил
Медные кабели до 17 м

Сетевая карта на 40 Гбит/с
Для PCI Express 2.0: (5 млрд. транзакций/c)
Сетевая карта на 40 Гбит/с
Для PCI Express 2.0: (5 млрд. транзакций/c)
 Массивы и структуры в MASM
Массивы и структуры в MASM Адсорбционные равновесия и процессы на подвижных поверхностях раздела. Структура биомембран
Адсорбционные равновесия и процессы на подвижных поверхностях раздела. Структура биомембран Конструирование ригеля
Конструирование ригеля Гражданское общество и государство
Гражданское общество и государство ТАМОЖЕННЫЕ ПРОЦЕДУРЫ
ТАМОЖЕННЫЕ ПРОЦЕДУРЫ Принятые основные символы и обозначения
Принятые основные символы и обозначения Внешнее и внутреннее строение насекомых
Внешнее и внутреннее строение насекомых  проверка безударных гласных - презентация для начальной школы
проверка безударных гласных - презентация для начальной школы Зависимые и независимые системы отопления зданий
Зависимые и независимые системы отопления зданий Курганы «с усами»
Курганы «с усами» Следственные и оперативно-розыскные ошибки: их профмлактика и устранение в состязательном процессе
Следственные и оперативно-розыскные ошибки: их профмлактика и устранение в состязательном процессе Методы исследования механической активности сердца
Методы исследования механической активности сердца Элементы вакуумной техники
Элементы вакуумной техники Классификация ограждающих конструкций. Расчет и конструирование дощатых настилов
Классификация ограждающих конструкций. Расчет и конструирование дощатых настилов Санитарно – гигиеническая оценка игрушки и книжных изданий.гигиена
Санитарно – гигиеническая оценка игрушки и книжных изданий.гигиена Острый аппендицит Кафедра хирургии № 2 ХНМУ
Острый аппендицит Кафедра хирургии № 2 ХНМУ  Диагностическое оборудование для контроля систем автомобиля
Диагностическое оборудование для контроля систем автомобиля Презентация на тему "Делинквентное поведение" - скачать презентации по Педагогике
Презентация на тему "Делинквентное поведение" - скачать презентации по Педагогике Презентация на тему "Федеральные государственные требования к структуре основной общеобразовательной программы дошкольного о
Презентация на тему "Федеральные государственные требования к структуре основной общеобразовательной программы дошкольного о Власть. Многообразие видов власти
Власть. Многообразие видов власти Представления и курсоры
Представления и курсоры Линейный алгоритм, записанный на алгоритмическом языке. Конкурс
Линейный алгоритм, записанный на алгоритмическом языке. Конкурс СТОЛБНЯК (Tetanus) (А35)
СТОЛБНЯК (Tetanus) (А35)  Organizatsia_sestrenskogo_ukhoda
Organizatsia_sestrenskogo_ukhoda Андрей Николаевич Туполев 1888 - 1972
Андрей Николаевич Туполев 1888 - 1972 Необходимость реформирования банковской системы Мирзошоев Ш Р Группа т 093
Необходимость реформирования банковской системы Мирзошоев Ш Р Группа т 093  Культура Древней Индии
Культура Древней Индии ИНФЕКЦИОННЫЙ ЭНДОКАРДИТ
ИНФЕКЦИОННЫЙ ЭНДОКАРДИТ