- Презентация "Параллельное программирование с OpenMP" - скачать презентации по Информатике

Содержание
- 2. Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ Содержание Трудно обнаруживаемые ошибки типа
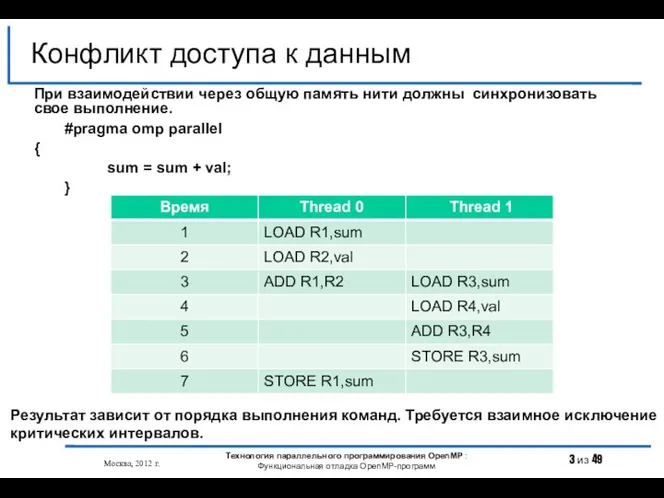
- 3. Конфликт доступа к данным Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ Результат
- 4. Ошибка возникает при одновременном выполнении следующих условий: Две или более нитей обращаются к одной и той
- 5. Использование различных компиляторов (различных опций оптимизации, включение/отключение режима отладки при компиляции программы), применение различных стратегий планирования
- 6. Конфликт доступа к данным Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ #define
- 7. Конфликт доступа к данным Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ #define
- 8. Конфликт доступа к данным Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ file1.c
- 9. Директива threadprivate threadprivate – переменные сохраняют глобальную область видимости внутри каждой нити #pragma omp threadprivate (Var)
- 10. Конфликт доступа к данным Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ file1.c
- 11. Конфликт доступа к данным Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ #define
- 12. Конфликт доступа к данным Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ #define
- 13. Конфликт доступа к данным Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ #define
- 14. Конфликт доступа к данным Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ void
- 15. Конфликт доступа к данным Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ void
- 16. Конфликт доступа к данным Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ void
- 17. Конфликт доступа к данным Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ void
- 18. Распределение циклов с зависимостью по данным. Организация конвейерного выполнения цикла. for(int i = 1; i for(int
- 19. Распределение циклов с зависимостью по данным. Организация конвейерного выполнения цикла. Технология параллельного программирования OpenMP : Функциональная
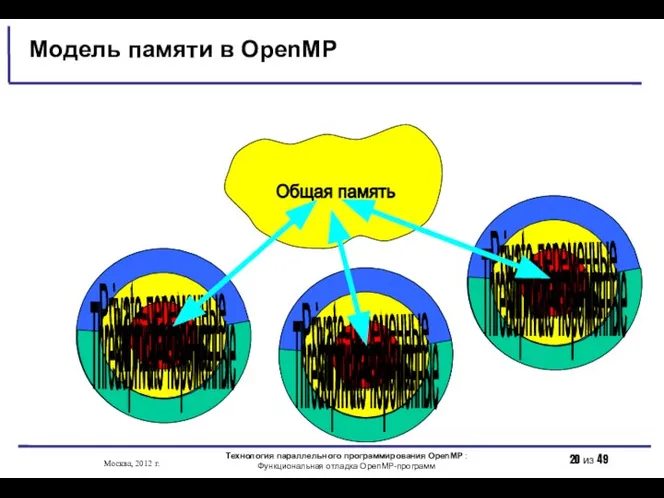
- 20. 001 Модель памяти в OpenMP Нить Кэш общих переменных Общая память Private-переменные Threadprivate-переменные 001 Нить Кэш
- 21. 001 Нить 0 Общая память 001 Нить 1 static int i = 0; … = i
- 22. Консистентность памяти в OpenMP Корректная последовательность работы нитей с переменной: Нить0 записывает значение переменной - write(var)
- 23. Распределение циклов с зависимостью по данным. Организация конвейерного выполнения цикла. Технология параллельного программирования OpenMP : Функциональная
- 24. Конфликт доступа к данным Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ #define
- 25. Конфликт доступа к данным Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ #define
- 26. Взаимная блокировка нитей Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ #define N
- 27. Семафоры в OpenMP Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ #include #define
- 28. Семафоры в OpenMP Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ #include #define
- 29. Взаимная блокировка нитей Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ #pragma omp
- 30. Взаимная блокировка нитей Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ #pragma omp
- 31. Неинициализированные переменные Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ #define N 100
- 32. Неинициализированные переменные Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ #define N 100
- 33. Неинициализированные переменные Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ int tmp =
- 34. Неинициализированные переменные Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ static int counter;
- 35. Неинициализированные переменные Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ static int counter;
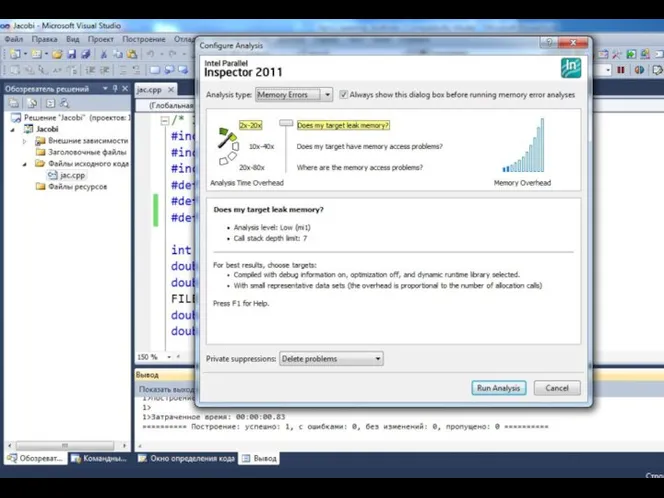
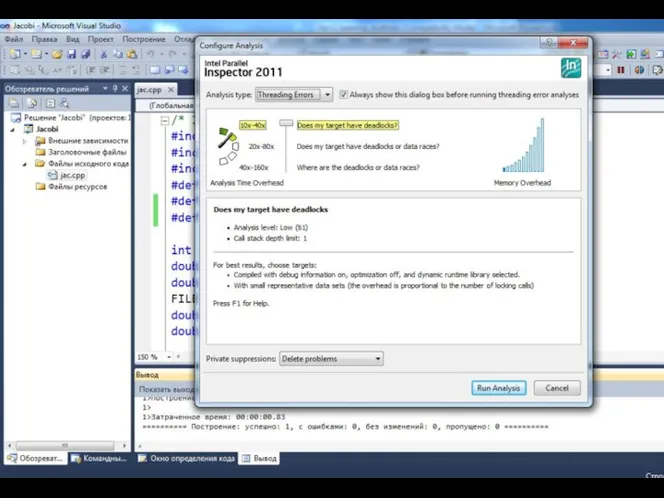
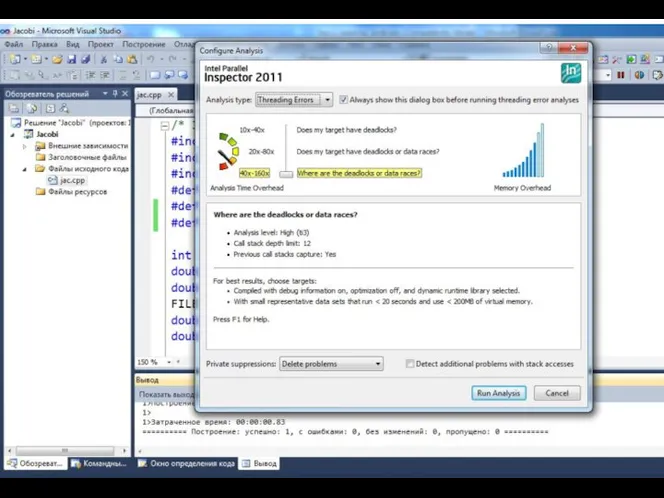
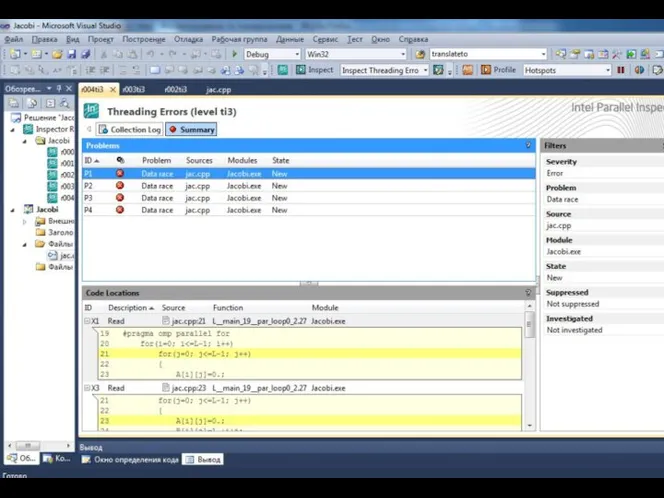
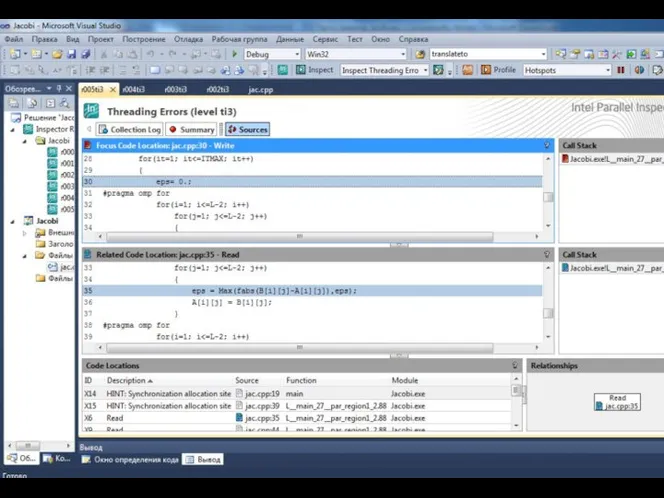
- 36. Автоматизированный поиск ошибок. Intel Thread Checker (Intel Parallel Inspector) Москва, 2012 г. Технология параллельного программирования OpenMP
- 37. Автоматизированный поиск ошибок. Intel Thread Checker Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка
- 38. Пакет тестов SPLASH-2 (Stanford Parallel Applications for Shared Memory) на 4-х ядерной машине Москва, 2012 г.
- 39. Автоматизированный поиск ошибок. Sun Thread Analyzer Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка
- 40. Автоматизированный поиск ошибок. Sun Thread Analyzer Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка
- 41. Intel Thread Checker и Sun Thread Analyzer Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная
- 47. Спасибо за внимание! Вопросы? Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ
- 48. Отладка эффективности OpenMP-программ. Следующая тема Москва, 2012 г. Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ
- 50. Скачать презентацию

Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ
Содержание
Трудно
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ
Содержание
Трудно
Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная

Ошибка возникает при одновременном выполнении следующих условий:
Две или более нитей обращаются
Ошибка возникает при одновременном выполнении следующих условий:
Две или более нитей обращаются

Использование различных компиляторов (различных опций оптимизации, включение/отключение режима отладки при компиляции
Использование различных компиляторов (различных опций оптимизации, включение/отключение режима отладки при компиляции

Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная

Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная

Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
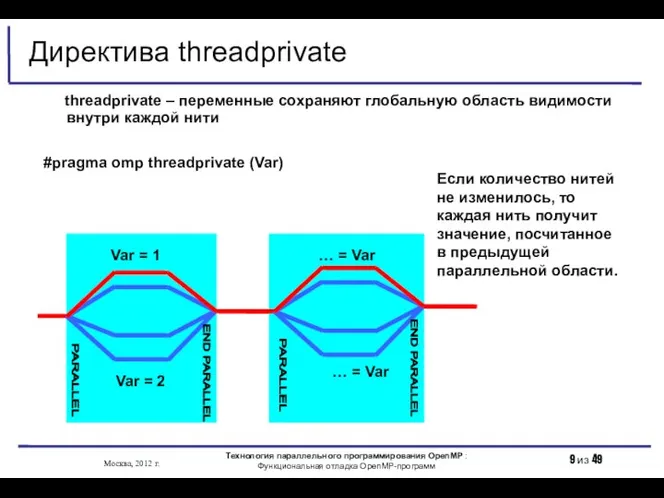
Директива threadprivate
threadprivate – переменные сохраняют глобальную область видимости внутри каждой
Директива threadprivate
threadprivate – переменные сохраняют глобальную область видимости внутри каждой

Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная

Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная

Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная

Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная

Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная

Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная

Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная

Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
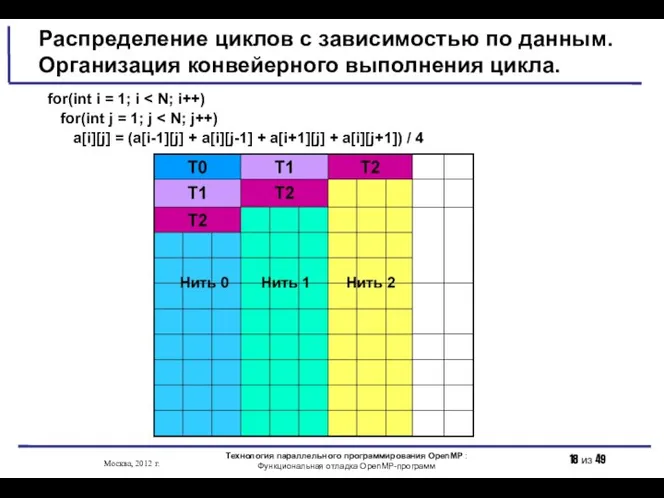
Распределение циклов с зависимостью по данным. Организация конвейерного выполнения цикла.
Распределение циклов с зависимостью по данным. Организация конвейерного выполнения цикла.

Распределение циклов с зависимостью по данным. Организация конвейерного выполнения цикла.
Технология
Распределение циклов с зависимостью по данным. Организация конвейерного выполнения цикла.
Технология
001
Модель памяти в OpenMP
Нить
Кэш общих переменных
Общая память
Private-переменные
Threadprivate-переменные
001
Нить
Кэш
001
Модель памяти в OpenMP
Нить
Кэш общих переменных
Общая память
Private-переменные
Threadprivate-переменные
001
Нить
Кэш
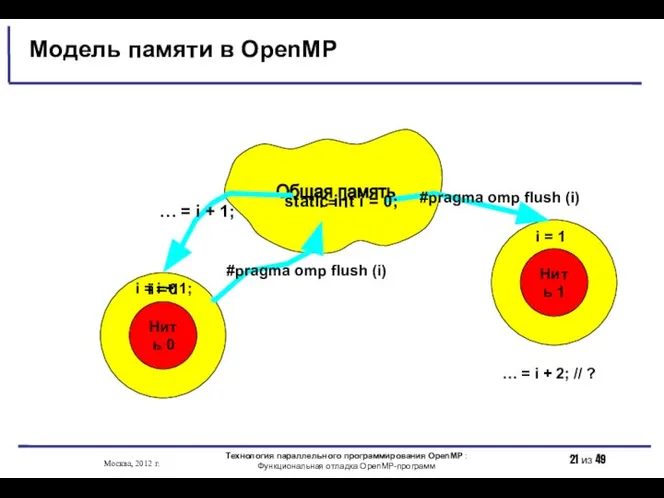
001
Нить 0
Общая память
001
Нить 1
static int i = 0;
… = i
001
Нить 0
Общая память
001
Нить 1
static int i = 0;
… = i

Консистентность памяти в OpenMP
Корректная последовательность работы нитей с переменной:
Нить0 записывает значение
Консистентность памяти в OpenMP
Корректная последовательность работы нитей с переменной:
Нить0 записывает значение

Распределение циклов с зависимостью по данным. Организация конвейерного выполнения цикла.
Технология
Распределение циклов с зависимостью по данным. Организация конвейерного выполнения цикла.
Технология

Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная

Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
Конфликт доступа к данным
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная

Взаимная блокировка нитей
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка
Взаимная блокировка нитей
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка

Семафоры в OpenMP
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка
Семафоры в OpenMP
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка
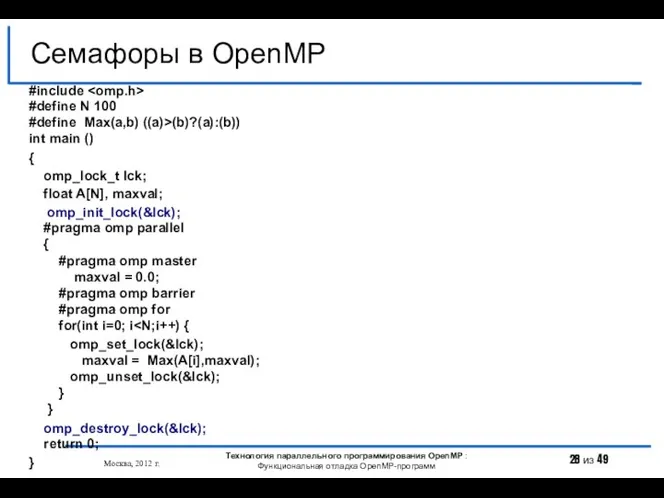
Семафоры в OpenMP
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка
Семафоры в OpenMP
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка

Взаимная блокировка нитей
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка
Взаимная блокировка нитей
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка

Взаимная блокировка нитей
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка
Взаимная блокировка нитей
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка

Неинициализированные переменные
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ
Неинициализированные переменные
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ

Неинициализированные переменные
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ
Неинициализированные переменные
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ

Неинициализированные переменные
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ
Неинициализированные переменные
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ

Неинициализированные переменные
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ
Неинициализированные переменные
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ

Неинициализированные переменные
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ
Неинициализированные переменные
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка OpenMP-программ

Автоматизированный поиск ошибок. Intel Thread Checker (Intel Parallel Inspector)
Москва, 2012 г.
Технология
Автоматизированный поиск ошибок. Intel Thread Checker (Intel Parallel Inspector)
Москва, 2012 г.
Технология

Автоматизированный поиск ошибок. Intel Thread Checker
Москва, 2012 г.
Технология параллельного программирования OpenMP
Автоматизированный поиск ошибок. Intel Thread Checker
Москва, 2012 г.
Технология параллельного программирования OpenMP
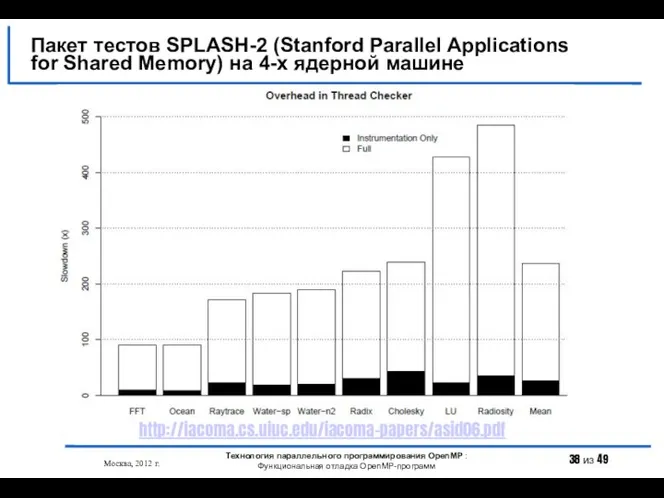
Пакет тестов SPLASH-2 (Stanford Parallel Applications for Shared Memory) на 4-х
Пакет тестов SPLASH-2 (Stanford Parallel Applications for Shared Memory) на 4-х

Автоматизированный поиск ошибок. Sun Thread Analyzer
Москва, 2012 г.
Технология параллельного программирования OpenMP
Автоматизированный поиск ошибок. Sun Thread Analyzer
Москва, 2012 г.
Технология параллельного программирования OpenMP

Автоматизированный поиск ошибок. Sun Thread Analyzer
Москва, 2012 г.
Технология параллельного программирования OpenMP
Автоматизированный поиск ошибок. Sun Thread Analyzer
Москва, 2012 г.
Технология параллельного программирования OpenMP
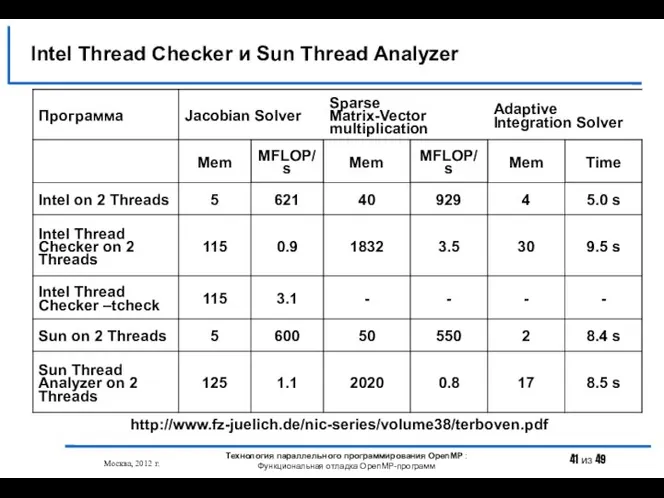
Intel Thread Checker и Sun Thread Analyzer
Москва, 2012 г.
Технология параллельного программирования
Intel Thread Checker и Sun Thread Analyzer
Москва, 2012 г.
Технология параллельного программирования

Спасибо за внимание!
Вопросы?
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка
Спасибо за внимание!
Вопросы?
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная отладка

Отладка эффективности OpenMP-программ.
Следующая тема
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
Отладка эффективности OpenMP-программ.
Следующая тема
Москва, 2012 г.
Технология параллельного программирования OpenMP : Функциональная
Похожие презентации
 Разработка информационной системы для ЗАО ГагаринКонсервМолоко
Разработка информационной системы для ЗАО ГагаринКонсервМолоко Симметричные криптосистемы. (Лекция 12)
Симметричные криптосистемы. (Лекция 12) Инструкция ОИ по работе с обращениями
Инструкция ОИ по работе с обращениями Информационная безопасность Основные понятия Законодательство в сфере защиты информации
Информационная безопасность Основные понятия Законодательство в сфере защиты информации Классификация языков программирования
Классификация языков программирования Носители информации
Носители информации Информация гарантированного доступа и иная общедоступная информация
Информация гарантированного доступа и иная общедоступная информация Абстрактные типы данных
Абстрактные типы данных Web of science. Мировая практика применения индекса цитирования при проведении научных исследований
Web of science. Мировая практика применения индекса цитирования при проведении научных исследований Компьютерные основы программирования. Представление данных часть 2
Компьютерные основы программирования. Представление данных часть 2
 Элементы теории погрешностей
Элементы теории погрешностей Big Data без «космоса» Как настроить и масштабировать работу с данными, если вы не Google… и даже не Yandex
Big Data без «космоса» Как настроить и масштабировать работу с данными, если вы не Google… и даже не Yandex Система контроля маневровых маршрутов. Технические решения
Система контроля маневровых маршрутов. Технические решения Устройства ввода
Устройства ввода Введение в массивы. Типы массивов в C#. Класс Array. (Модуль 5)
Введение в массивы. Типы массивов в C#. Класс Array. (Модуль 5) Форматирование текста
Форматирование текста Операционная система Android
Операционная система Android Аттестационная работа. Применение проектной и исследовательской деятельности на уроках информатики через межпредметную связь
Аттестационная работа. Применение проектной и исследовательской деятельности на уроках информатики через межпредметную связь Введение в информатику. Лекция 1
Введение в информатику. Лекция 1 Шрек. Игра
Шрек. Игра Презентация на тему: «СУБД Access. Понятие запроса» Выполнила: Часовских Екатерина студентка 1 курса отделения финансы и кредит
Презентация на тему: «СУБД Access. Понятие запроса» Выполнила: Часовских Екатерина студентка 1 курса отделения финансы и кредит Анализ рисков программного проекта
Анализ рисков программного проекта Системное моделирование для разработки требований. (Лекция 3)
Системное моделирование для разработки требований. (Лекция 3) Разработка интеллектуальной системы управления контентом предприятия
Разработка интеллектуальной системы управления контентом предприятия Растровое кодирование графической информации
Растровое кодирование графической информации Презентация "Базы данных 1" - скачать презентации по Информатике
Презентация "Базы данных 1" - скачать презентации по Информатике Законы управления при использовании информационных систем управления
Законы управления при использовании информационных систем управления