- Методы математической статистики в психологопедагогических исследованиях

Содержание
- 2. Наиболее часто статистическая обработка данных в психологических исследованиях включает: Выявление различий между двумя группами признаков (критерий
- 3. Понятие статистической значимости Уровень статистической значимости (р) указывает на вероятность того, что результаты не представляют генеральную
- 4. Меры центральной тенденции группа методов, которые указывают наиболее типичный результат, характеризующий выполнение теста всей группой: среднеарифметическое
- 5. Среднеарифметическое значение (М) Определяется по формуле: М = где М - среднеарифметическое значение n - количество
- 6. Мода (Мо) - наиболее часто встречающийся результат. Мода определяется как середина интервала, для которого частота максимальна.
- 7. Медиана (Ме) - результат, находящийся в середине последовательности показателей, если их расположить в порядке возрастания или
- 8. Меры разброса данных характеризуют степень индивидуальных отклонений от центральной тенденции (разность между максимальной и минимальной величинами
- 9. Дисперсия - характеризует насколько частные значения отклоняются от средней величины в данной выборке. Чем больше дисперсия,
- 10. Общий алгоритм вычисления дисперсии Вычисляется среднее по выборке Для каждого элемента выборки вычисляется его отклонение от
- 11. Пример: вычислим дисперсию для следующего ряда: 2, 4, 6, 8, 10. Найдем среднее (М) для данного
- 12. Стандартное отклонение (σ) позволяет сказать, насколько большая часть результатов данного исследования отклоняется от среднего значения. Вычисляется
- 13. Пример расчета среднего квадратичного отклонения (σ): Опыт работы у пяти испытуемых составляет: 2,3,4,7 и 9 лет
- 14. Оценка достоверности отличий по t-критерию Стьюдента Вычисление первичных статистик: n – количество показателей; M – средняя
- 15. Оформление данных в таблицы Показатели, характеризующие общение дошкольников со сверстниками (экспериментальная группа 1)
- 16. Оформление данных в таблицы Показатели, характеризующие общение дошкольников со сверстниками (экспериментальная группа 2)
- 17. Расчет t-критерия Стьюдента где M1 и M2 — значения сравниваемых средних арифметических; tSt — величина вычисленного
- 18. Оформление данных в таблицы Сравнительная характеристика выраженности показателей общения со сверстниками детей старшего дошкольного возраста (экспериментальные
- 19. Статистическое сравнение средних значений показателей выраженности форм общения с родителями детей старшего дошкольного возраста (методика Е.О.
- 20. Корреляционный анализ Корреляционный анализ дает возможность количественной оценки степени согласованности (взаимосвязи) различных показателей Наличие корреляции между
- 21. Расчет коэффициента корреляции (r) Спирмена Правила ранжирования Меньшему значению начисляется меньший ранг. Наименьшему значению начисляется ранг
- 22. Коэффициент ранговой корреляции Спирмена (rs) подсчитывается по формуле: где d - разность между рангами по двум
- 23. Пример: Расчет для рангового коэффициента корреляции Спирмена при сопоставлении показателей количества ошибок и показателей интеллекта у
- 24. Классификация корреляционных связей Высокозначимая корреляция – при r, соответствующем уровню статистической значимости p≤0,01; Значимая корреляция –
- 25. Выявление взаимосвязи родительского отношения и особенностей общения детей старшего дошкольного возраста со сверстниками Оформление данных в
- 27. Скачать презентацию

Наиболее часто статистическая обработка данных в психологических исследованиях включает:
Выявление различий между
Наиболее часто статистическая обработка данных в психологических исследованиях включает:
Выявление различий между
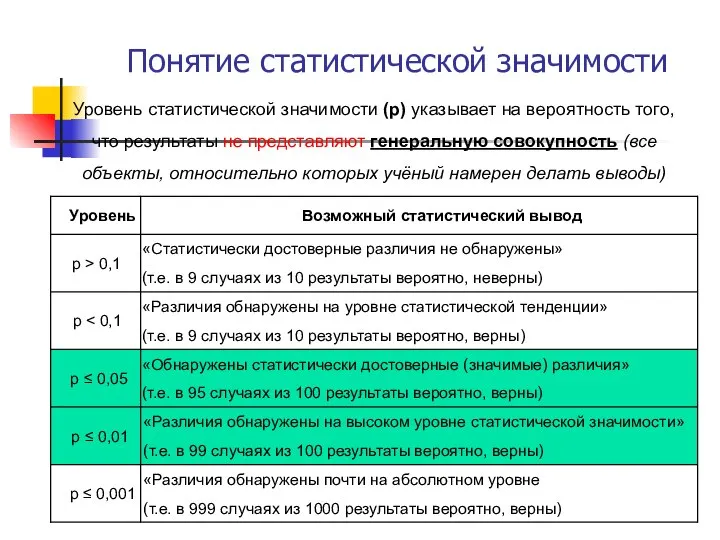
Понятие статистической значимости
Уровень статистической значимости (р) указывает на вероятность того, что
Понятие статистической значимости
Уровень статистической значимости (р) указывает на вероятность того, что

Меры центральной тенденции
группа методов, которые указывают наиболее типичный результат, характеризующий выполнение
Меры центральной тенденции
группа методов, которые указывают наиболее типичный результат, характеризующий выполнение

Среднеарифметическое значение (М)
Определяется по формуле:
М =
где М - среднеарифметическое
Среднеарифметическое значение (М)
Определяется по формуле:
М =
где М - среднеарифметическое

Мода (Мо)
- наиболее часто встречающийся результат.
Мода определяется как середина интервала, для которого
Мода (Мо)
- наиболее часто встречающийся результат.
Мода определяется как середина интервала, для которого

Медиана (Ме)
- результат, находящийся в середине последовательности показателей, если их расположить
Медиана (Ме)
- результат, находящийся в середине последовательности показателей, если их расположить

Меры разброса данных
характеризуют степень индивидуальных отклонений от центральной тенденции (разность между
Меры разброса данных
характеризуют степень индивидуальных отклонений от центральной тенденции (разность между

Дисперсия
- характеризует насколько частные значения отклоняются от средней величины в данной
Дисперсия
- характеризует насколько частные значения отклоняются от средней величины в данной

Общий алгоритм вычисления дисперсии
Вычисляется среднее по выборке
Для каждого элемента выборки вычисляется
Общий алгоритм вычисления дисперсии
Вычисляется среднее по выборке
Для каждого элемента выборки вычисляется

Пример: вычислим дисперсию для следующего ряда: 2, 4, 6, 8, 10.
Пример: вычислим дисперсию для следующего ряда: 2, 4, 6, 8, 10.

Стандартное отклонение (σ)
позволяет сказать, насколько большая часть результатов данного исследования отклоняется
Стандартное отклонение (σ)
позволяет сказать, насколько большая часть результатов данного исследования отклоняется

Пример расчета среднего квадратичного отклонения (σ):
Опыт работы у пяти испытуемых составляет:
Пример расчета среднего квадратичного отклонения (σ):
Опыт работы у пяти испытуемых составляет:

Оценка достоверности отличий по t-критерию Стьюдента
Вычисление первичных статистик:
n – количество показателей;
M
Оценка достоверности отличий по t-критерию Стьюдента
Вычисление первичных статистик:
n – количество показателей;
M
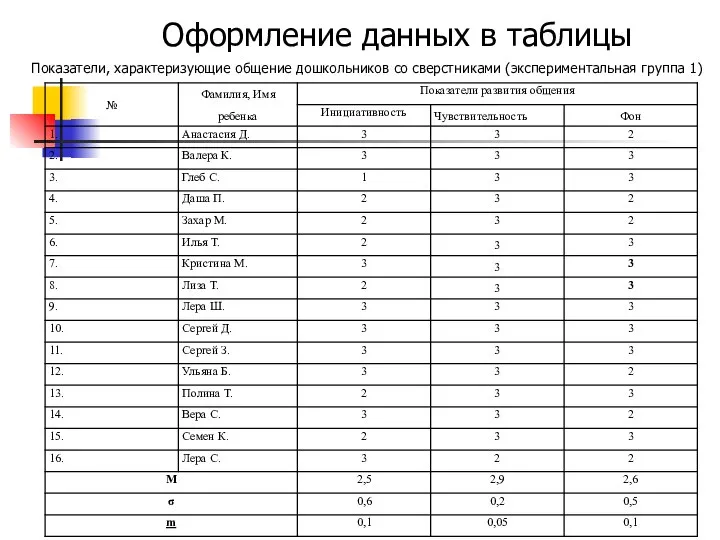
Оформление данных в таблицы
Показатели, характеризующие общение дошкольников со сверстниками (экспериментальная группа
Оформление данных в таблицы
Показатели, характеризующие общение дошкольников со сверстниками (экспериментальная группа
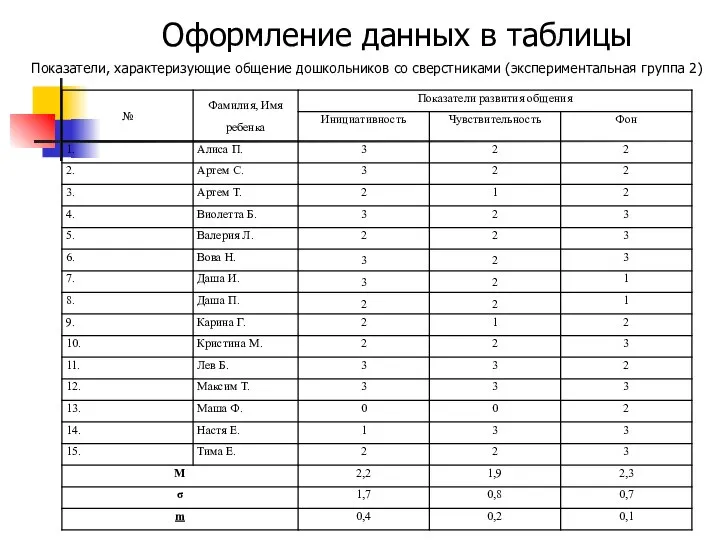
Оформление данных в таблицы
Показатели, характеризующие общение дошкольников со сверстниками (экспериментальная группа
Оформление данных в таблицы
Показатели, характеризующие общение дошкольников со сверстниками (экспериментальная группа

Расчет t-критерия Стьюдента
где M1 и M2 — значения сравниваемых средних арифметических;
tSt
Расчет t-критерия Стьюдента
где M1 и M2 — значения сравниваемых средних арифметических;
tSt
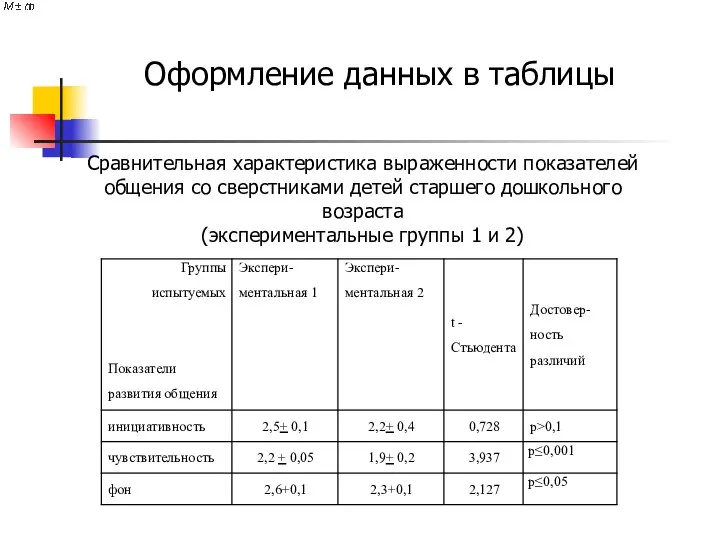
Оформление данных в таблицы
Сравнительная характеристика выраженности показателей
общения со сверстниками детей старшего
Оформление данных в таблицы
Сравнительная характеристика выраженности показателей
общения со сверстниками детей старшего
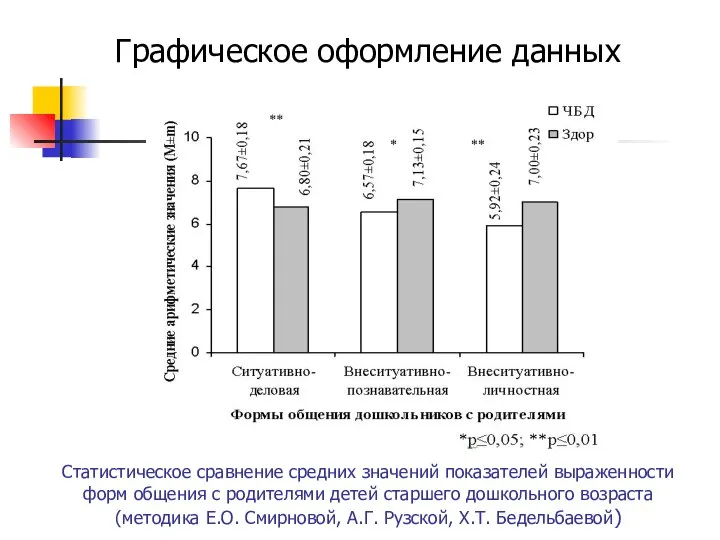
Статистическое сравнение средних значений показателей выраженности форм общения с родителями детей
Статистическое сравнение средних значений показателей выраженности форм общения с родителями детей

Корреляционный анализ
Корреляционный анализ дает возможность количественной оценки степени согласованности (взаимосвязи) различных
Корреляционный анализ
Корреляционный анализ дает возможность количественной оценки степени согласованности (взаимосвязи) различных

Расчет коэффициента корреляции (r) Спирмена
Правила ранжирования
Меньшему значению начисляется меньший ранг.
Наименьшему значению
Расчет коэффициента корреляции (r) Спирмена
Правила ранжирования
Меньшему значению начисляется меньший ранг.
Наименьшему значению

Коэффициент ранговой корреляции Спирмена (rs) подсчитывается по формуле:
где d - разность
Коэффициент ранговой корреляции Спирмена (rs) подсчитывается по формуле:
где d - разность
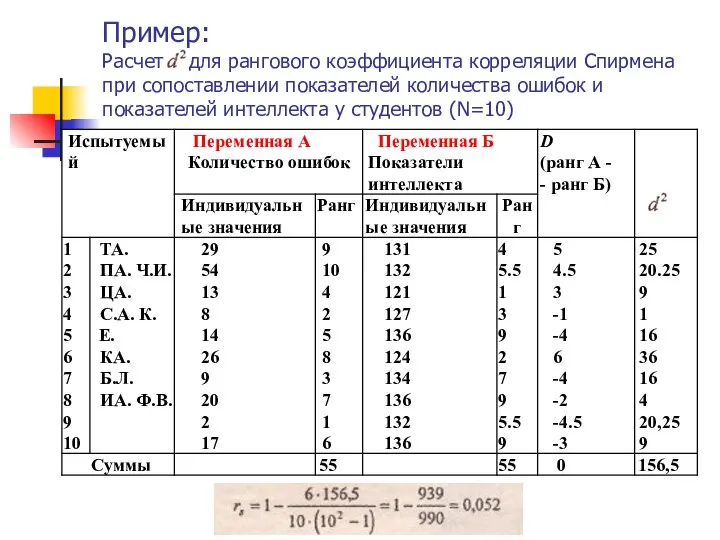
Пример:
Расчет для рангового коэффициента корреляции Спирмена при сопоставлении показателей количества ошибок
Пример: Расчет для рангового коэффициента корреляции Спирмена при сопоставлении показателей количества ошибок

Классификация корреляционных связей
Высокозначимая корреляция – при r, соответствующем уровню статистической значимости
Классификация корреляционных связей
Высокозначимая корреляция – при r, соответствующем уровню статистической значимости
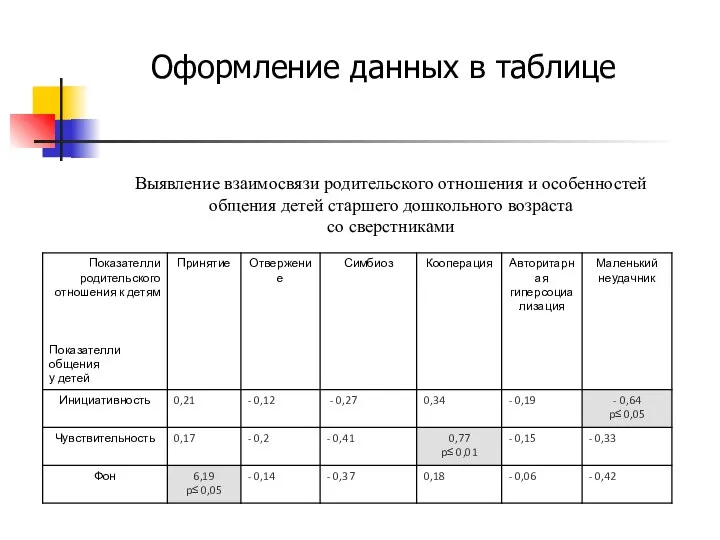
Выявление взаимосвязи родительского отношения и особенностей общения детей старшего дошкольного возраста
со
Выявление взаимосвязи родительского отношения и особенностей общения детей старшего дошкольного возраста
со
 Число и цифра 3
Число и цифра 3 Тест. Толерантность + Математика
Тест. Толерантность + Математика Квадрат. Удивительные свойства квадрата Шарапова Мария, 6 класс МОУ СОШ № 37
Квадрат. Удивительные свойства квадрата Шарапова Мария, 6 класс МОУ СОШ № 37  Доли. Обыкновенные дроби
Доли. Обыкновенные дроби Решение заданий №6 (параллелограмм) по материалам открытого банка задач ЕГЭ по математике 2016 года
Решение заданий №6 (параллелограмм) по материалам открытого банка задач ЕГЭ по математике 2016 года Прямоугольный параллелепипед
Прямоугольный параллелепипед Компланарные вектора
Компланарные вектора Аттестационная работа. Проектная деятельность на уроках математики. (5-6 класс)
Аттестационная работа. Проектная деятельность на уроках математики. (5-6 класс) Решение логарифмических уравнений и неравенств
Решение логарифмических уравнений и неравенств Квадратные уравнения
Квадратные уравнения Теорема Пифагора
Теорема Пифагора Устная разминка на уроке математики
Устная разминка на уроке математики Урок математики Вычитание с переходом через десяток
Урок математики Вычитание с переходом через десяток  Соотношения между сторонами и углами прямоугольного треугольника. Решение задач
Соотношения между сторонами и углами прямоугольного треугольника. Решение задач Презентация по математике "Красота в симетрии" - скачать
Презентация по математике "Красота в симетрии" - скачать  Система подготовки к ОГЭ по математике
Система подготовки к ОГЭ по математике Функции и их свойства
Функции и их свойства Математична модель оцінювання сталого розвитку
Математична модель оцінювання сталого розвитку Правило умножения для комбинаторных задач
Правило умножения для комбинаторных задач Нахождение числа по его дроби
Нахождение числа по его дроби Обзор численных методов
Обзор численных методов Рациональные уравнения
Рациональные уравнения Обыкновенные дроби. Сокращение дробей
Обыкновенные дроби. Сокращение дробей Решение задач с помощью квадратных уравнений
Решение задач с помощью квадратных уравнений Объем цилиндра
Объем цилиндра Математический диктант Равнобедренный треугольник. Признаки равенства треугольников. МБОУ СОШ с.Ургала Хазиахметова Г.С.
Математический диктант Равнобедренный треугольник. Признаки равенства треугольников. МБОУ СОШ с.Ургала Хазиахметова Г.С.  24.02.2010г. Дифференцирование частного и степени. Дернова А.М. учитель математики Iкв.к. МБОУ «Новотроицкая СОШ»
24.02.2010г. Дифференцирование частного и степени. Дернова А.М. учитель математики Iкв.к. МБОУ «Новотроицкая СОШ»  Преобразование выражения A sin x + B cos х к виду С sin(x+t)
Преобразование выражения A sin x + B cos х к виду С sin(x+t)