- Задача кластеризации. Алгоритмы кластеризации

Содержание
- 2. Кластеризация — группировка объектов по похожести их свойств; каждый кластер состоит из схожих объектов, а объекты
- 3. Цели кластеризации в Data Mining могут быть различными и зависят от конкретной решаемой задачи. Рассмотрим эти
- 4. Алгоритмы кластеризации К-средних (K-means) Нейронная сеть Кохонена Графовые алгоритмы кластеризации Статистические алгоритмы кластеризации Алгоритмы семейства FOREL
- 5. Алгоритм кластеризации k-means От англ. mean — «среднее значение». Он состоит из четырех шагов. Задается число
- 6. Например, если в кластер вошли три записи с наборами признаков (х1, у1), (х2,у2), (х3, у3), то
- 7. Шаги 3 и 4 повторяются до тех пор, пока выполнение алгоритма не будет прервано либо пока
- 8. Меры расстояний Ключевой момент алгоритма k-means: на каждой итерации вычисляется расстояние между записями и центрами кластеров,
- 9. □ Расстояние Манхэттена (Manhattan distance), или метрика L1 вычисляется по формуле □ Для категориальных признаков в
- 10. Пример работы алгоритма k-means Пусть имеется набор из 8 точек данных в двумерном пространстве, из которого
- 11. Шаг 1. Определим число кластеров, на которое требуется разбить исходное множество: k= 2. Шаг 2. Случайным
- 13. Таким образом, кластер 1 содержит точки А, Е, G, а кластер 2 — точки В, С,
- 14. На рис. начальные центры кластеров представлены светлыми ромбами, а центроиды, вычисленные при первом проходе алгоритма, —
- 15. Шаг 3, проход 2. После того как найдены новые центры кластеров, для каждой точки снова определяется
- 16. Таким образом, кластер 1 будет содержать точки А, Е, G, Н, а кластер 2 — В,
- 17. Шаг 4, проход 2. Для каждого кластера вновь вычисляется центроид, и центр кластера перемещается в него.
- 18. По сравнению с предыдущим проходом центры кластеров изменились незначительно. Шаг 3, проход 3. Для каждой записи
- 19. Следует отметить, что записей, сменивших кластер на третьем проходе алгоритма, не было. Новая сумма квадратов ошибок
- 20. Таким образом, сумма квадратов ошибок изменилась незначительно по сравнению с предыдущим проходом. Шаг 4, проход 3.
- 21. Сети Кохонена Термин «сети Кохонена» был введен в 1982 г. финским ученым Тойво Кохоненом. Сети Кохонена
- 22. Объекты имеют 3 признака (на самом деле их может быть любое количество). Теперь представим, что все
- 23. Взглянув на рисунок, можно увидеть, как расположены объекты в пространстве, причем легко заметить участки, где объекты
- 25. Берем один объект (точку в этом пространстве) и находим ближайший к нему узел сети. После этого
- 27. В основе построения сети Кохонена лежит конкурентное обучение, когда выходные узлы (нейроны) конкурируют между собой за
- 28. Входные нейроны образуют входной слой сети, который содержит по одному нейрону для каждого входного поля. Как
- 29. Однако в отличие от большинства нейронных сетей других видов сеть Кохонена не имеет скрытых слоев: данные
- 30. В процессе обучения и функционирования сеть KCN выполняет три процедуры. Конкуренция. Выходные нейроны конкурируют между собой
- 31. 3. Подстройка весов. Нейроны, соседние с нейроном-победителем, участвуют в подстройке весов, то есть в обучении. Веса
- 32. Обучение сети Кохонена Сети Кохонена — это нейросетевые структуры, в которых используется алгоритм обучения Кохонена. Рассмотрим
- 33. Алгоритм Кохонена включает шаги: Инициализация. Для нейронов сети устанавливаются начальные веса, а также задаются начальная скорость
- 34. Иными словами, рассчитывается расстояние между векторами весов всех нейронов выходного слоя и вектором входного воздействия. Тот
- 36. Пример работы сети Кохонена Имеется множество данных; в нем содержатся атрибуты Возраст и Доход. Для решения
- 38. Для первого входного вектора X1 = (0,8; 0,8) выполним такие действия, как конкуренция, объединение и подстройка.
- 39. Таким образом, для первой записи победителем стал нейрон с номером 1, для которого расстояние между вектором
- 40. Тогда для признака Возраст: Тогда для признака Доход: Веса «подталкиваются» в направлении значений входных полей записи,
- 41. Произведем аналогичные действия для второго входного вектора Х2 = (0,8; 0,1). Конкуренция.
- 42. Таким образом, для второй записи победителем стал нейрон 2. Обратим внимание на то, что он выиграл
- 43. Как можно увидеть, веса вновь корректируются в направлении значений входных полей записи. Вес w12 подстраивается так
- 44. Теперь выполним ту же последовательность действий для третьей записи, где входной вектор Х3 = (0,2; 0,9).
- 45. Теперь победителем стал нейрон 3, поскольку вектор его весов W3 = (0,1; 0,8) оказался ближе к
- 46. И наконец выполним ту же последовательность действий для входного вектора четвертой записи Х4 = (0,1; 0,1).
- 47. Теперь победителем стал нейрон 4, поскольку вектор его весов W4 = (0,1; 0,2) оказался ближе к
- 48. Таким образом, можно увидеть, что четыре выходных нейрона представляют четыре различных кластера, если выборка данных содержит
- 50. Карты Кохонена Самоорганизующиеся карты признаков не только являются эффективным алгоритмом кластеризации, но и позволяют представлять ее
- 51. В большинстве практических приложений приходится иметь дело с данными, для которых размерность пространства признаков больше, чем
- 52. Методика построения карты Чем отличаются понятия «сеть Кохонена» и «карта Кохонена»? сеть Кохонена используется только для
- 53. Карта Кохонена состоит из сегментов прямоугольной или шестиугольной формы, называемых ячейками. Каждая ячейка связана с определенным
- 54. Хотя расстояние между объектами позволяет сделать выводы о степени их сходства или различия, также важна информация
- 55. В зависимости от значения признака определяется цвет для всех объектов в ячейке. Например, пусть в некоторую
- 57. Скачать презентацию

Кластеризация — группировка объектов по похожести их свойств; каждый кластер состоит
Кластеризация — группировка объектов по похожести их свойств; каждый кластер состоит

Цели кластеризации в Data Mining могут быть различными и зависят от
Цели кластеризации в Data Mining могут быть различными и зависят от

Алгоритмы кластеризации
К-средних (K-means)
Нейронная сеть Кохонена
Графовые алгоритмы кластеризации
Статистические алгоритмы кластеризации
Алгоритмы
Алгоритмы кластеризации
К-средних (K-means)
Нейронная сеть Кохонена
Графовые алгоритмы кластеризации
Статистические алгоритмы кластеризации
Алгоритмы

Алгоритм кластеризации k-means
От англ. mean — «среднее значение». Он состоит
Алгоритм кластеризации k-means
От англ. mean — «среднее значение». Он состоит

Например, если в кластер вошли три записи с наборами признаков (х1,
Например, если в кластер вошли три записи с наборами признаков (х1,

Шаги 3 и 4 повторяются до тех пор, пока выполнение алгоритма
Шаги 3 и 4 повторяются до тех пор, пока выполнение алгоритма

Меры расстояний
Ключевой момент алгоритма k-means: на каждой итерации вычисляется расстояние между
Меры расстояний
Ключевой момент алгоритма k-means: на каждой итерации вычисляется расстояние между

□ Расстояние Манхэттена (Manhattan distance), или метрика L1 вычисляется по формуле
□ Расстояние Манхэттена (Manhattan distance), или метрика L1 вычисляется по формуле

Пример работы алгоритма k-means
Пусть имеется набор из 8 точек данных в
Пример работы алгоритма k-means
Пусть имеется набор из 8 точек данных в

Шаг 1. Определим число кластеров, на которое требуется разбить исходное множество:
Шаг 1. Определим число кластеров, на которое требуется разбить исходное множество:


Таким образом, кластер 1 содержит точки А, Е, G, а кластер
Таким образом, кластер 1 содержит точки А, Е, G, а кластер

На рис. начальные центры кластеров представлены светлыми ромбами, а центроиды, вычисленные
На рис. начальные центры кластеров представлены светлыми ромбами, а центроиды, вычисленные
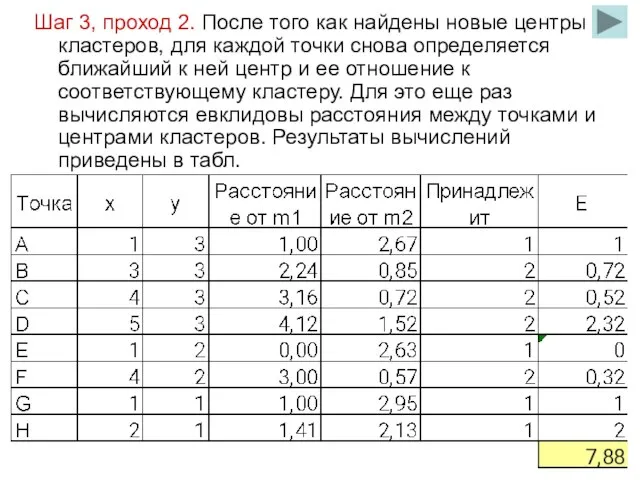
Шаг 3, проход 2. После того как найдены новые центры кластеров,
Шаг 3, проход 2. После того как найдены новые центры кластеров,

Таким образом, кластер 1 будет содержать точки А, Е, G, Н,
Таким образом, кластер 1 будет содержать точки А, Е, G, Н,

Шаг 4, проход 2. Для каждого кластера вновь вычисляется центроид, и
Шаг 4, проход 2. Для каждого кластера вновь вычисляется центроид, и

По сравнению с предыдущим проходом центры кластеров изменились незначительно.
Шаг 3, проход
По сравнению с предыдущим проходом центры кластеров изменились незначительно.
Шаг 3, проход

Следует отметить, что записей, сменивших кластер на третьем проходе алгоритма, не
Следует отметить, что записей, сменивших кластер на третьем проходе алгоритма, не

Таким образом, сумма квадратов ошибок изменилась незначительно по сравнению с предыдущим
Таким образом, сумма квадратов ошибок изменилась незначительно по сравнению с предыдущим

Сети Кохонена
Термин «сети Кохонена» был введен в 1982 г. финским ученым
Сети Кохонена
Термин «сети Кохонена» был введен в 1982 г. финским ученым

Объекты имеют 3 признака (на самом деле их может быть любое
Объекты имеют 3 признака (на самом деле их может быть любое

Взглянув на рисунок, можно увидеть, как расположены объекты в пространстве, причем
Взглянув на рисунок, можно увидеть, как расположены объекты в пространстве, причем


Берем один объект (точку в этом пространстве) и находим ближайший к
Берем один объект (точку в этом пространстве) и находим ближайший к


В основе построения сети Кохонена лежит конкурентное обучение, когда выходные узлы
В основе построения сети Кохонена лежит конкурентное обучение, когда выходные узлы

Входные нейроны образуют входной слой сети, который содержит по одному нейрону
Входные нейроны образуют входной слой сети, который содержит по одному нейрону

Однако в отличие от большинства нейронных сетей других видов сеть Кохонена
Однако в отличие от большинства нейронных сетей других видов сеть Кохонена

В процессе обучения и функционирования сеть KCN выполняет три процедуры.
Конкуренция. Выходные
В процессе обучения и функционирования сеть KCN выполняет три процедуры.
Конкуренция. Выходные

3. Подстройка весов. Нейроны, соседние с нейроном-победителем, участвуют в подстройке весов,
3. Подстройка весов. Нейроны, соседние с нейроном-победителем, участвуют в подстройке весов,

Обучение сети Кохонена
Сети Кохонена — это нейросетевые структуры, в которых используется
Обучение сети Кохонена
Сети Кохонена — это нейросетевые структуры, в которых используется

Алгоритм Кохонена включает шаги:
Инициализация. Для нейронов сети устанавливаются начальные веса, а
Алгоритм Кохонена включает шаги:
Инициализация. Для нейронов сети устанавливаются начальные веса, а

Иными словами, рассчитывается расстояние между векторами весов всех нейронов выходного слоя
Иными словами, рассчитывается расстояние между векторами весов всех нейронов выходного слоя


Пример работы сети Кохонена
Имеется множество данных; в нем содержатся атрибуты Возраст
Пример работы сети Кохонена
Имеется множество данных; в нем содержатся атрибуты Возраст


Для первого входного вектора X1 = (0,8; 0,8) выполним такие действия,
Для первого входного вектора X1 = (0,8; 0,8) выполним такие действия,

Таким образом, для первой записи победителем стал нейрон с номером 1,
Таким образом, для первой записи победителем стал нейрон с номером 1,

Тогда для признака Возраст:
Тогда для признака Доход:
Веса «подталкиваются» в направлении значений
Тогда для признака Возраст:
Тогда для признака Доход:
Веса «подталкиваются» в направлении значений

Произведем аналогичные действия для второго входного вектора Х2 = (0,8; 0,1).
Произведем аналогичные действия для второго входного вектора Х2 = (0,8; 0,1).

Таким образом, для второй записи победителем стал нейрон 2. Обратим внимание
Таким образом, для второй записи победителем стал нейрон 2. Обратим внимание

Как можно увидеть, веса вновь корректируются в направлении значений входных полей
Как можно увидеть, веса вновь корректируются в направлении значений входных полей

Теперь выполним ту же последовательность действий для третьей записи, где входной
Теперь выполним ту же последовательность действий для третьей записи, где входной

Теперь победителем стал нейрон 3, поскольку вектор его весов W3 =
Теперь победителем стал нейрон 3, поскольку вектор его весов W3 =

И наконец выполним ту же последовательность действий для входного вектора четвертой
И наконец выполним ту же последовательность действий для входного вектора четвертой

Теперь победителем стал нейрон 4, поскольку вектор его весов W4 =
Теперь победителем стал нейрон 4, поскольку вектор его весов W4 =

Таким образом, можно увидеть, что четыре выходных нейрона представляют четыре различных
Таким образом, можно увидеть, что четыре выходных нейрона представляют четыре различных


Карты Кохонена
Самоорганизующиеся карты признаков не только являются эффективным алгоритмом кластеризации,
Карты Кохонена
Самоорганизующиеся карты признаков не только являются эффективным алгоритмом кластеризации,

В большинстве практических приложений приходится иметь дело с данными, для которых
В большинстве практических приложений приходится иметь дело с данными, для которых

Методика построения карты
Чем отличаются понятия «сеть Кохонена» и «карта Кохонена»?
Методика построения карты
Чем отличаются понятия «сеть Кохонена» и «карта Кохонена»?
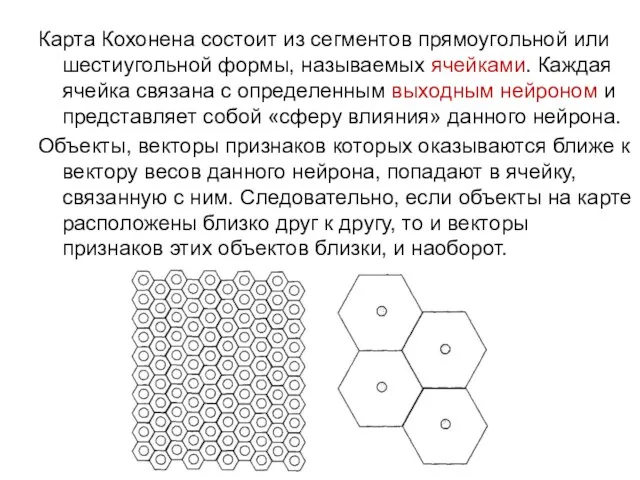
Карта Кохонена состоит из сегментов прямоугольной или шестиугольной формы, называемых ячейками.
Карта Кохонена состоит из сегментов прямоугольной или шестиугольной формы, называемых ячейками.

Хотя расстояние между объектами позволяет сделать выводы о степени их сходства
Хотя расстояние между объектами позволяет сделать выводы о степени их сходства

В зависимости от значения признака определяется цвет для всех объектов в
В зависимости от значения признака определяется цвет для всех объектов в
 Своя игра. Математический турнир
Своя игра. Математический турнир Объём усечённого конуса
Объём усечённого конуса Деление круглых чисел
Деление круглых чисел Учимся играя. Счёт до 2
Учимся играя. Счёт до 2 Свойства ранга матрицы
Свойства ранга матрицы Введение в теорию вероятностей. Логические операции над множествами. Элементы комбинаторики
Введение в теорию вероятностей. Логические операции над множествами. Элементы комбинаторики Объемы геометрических тел
Объемы геометрических тел Прямоугольный треугольник. Решение задач
Прямоугольный треугольник. Решение задач Одночлен и его стандартный вид
Одночлен и его стандартный вид Прямоугольный параллелепипед. Куб. Презентация
Прямоугольный параллелепипед. Куб. Презентация Линейная функция и ее график
Линейная функция и ее график Числа в загадках, пословицах и поговорках
Числа в загадках, пословицах и поговорках Производная сложной функции
Производная сложной функции Решение логической задачи (1 класс)
Решение логической задачи (1 класс) Параллельные прямые в пространстве
Параллельные прямые в пространстве Решение экстремальных задач теории графов перебором
Решение экстремальных задач теории графов перебором Метрические пространства
Метрические пространства Числовой отрезок. Урок 24
Числовой отрезок. Урок 24 Сопряжение
Сопряжение Массивы. Двумерные массивы. Спиралевидный и змеевидный обходы
Массивы. Двумерные массивы. Спиралевидный и змеевидный обходы Сравнение отрезков
Сравнение отрезков Понятие объема. Объем прямоугольного параллелепипеда
Понятие объема. Объем прямоугольного параллелепипеда Устные вычисления. Решение задач. Сумма длин отрезков
Устные вычисления. Решение задач. Сумма длин отрезков Числовые функции (Количество и сумма натуральных делителей числа. Функция Эйлера). Лекция 2
Числовые функции (Количество и сумма натуральных делителей числа. Функция Эйлера). Лекция 2 Теорія ймовірностей. Основні поняття теорії ймовірностей (лекція 5)
Теорія ймовірностей. Основні поняття теорії ймовірностей (лекція 5) Смешанные числа
Смешанные числа Цилиндр
Цилиндр Модель парной линейной регрессии
Модель парной линейной регрессии