- Дискриминантный, факторный, кластерный анализ

Содержание
- 2. Дискриминантный анализ У нас есть зверьки разного возраста, у которых измеряли 20 показателей. По каким из
- 3. Для решения таких задач создан ДИСКРИМИНАНТНЫЙ АНАЛИЗ (discriminant function analysis) Основная идея: Мы измерили целый набор
- 4. Дискриминантный анализ Суть анализа: Очень близок ANOVA. Проверяет, отличаются ли группы на основе СРЕДНИХ ЗНАЧЕНИЙ переменных.
- 5. На каждом шаге (для каждой переменной) считается статистика F, т.е. мы сравниваем группы по этой переменной.
- 6. Мы изучаем лемуров на Мадагаскаре. У нас 3 вида лемуров, мы поймали зверьков разных видов, взвесили,
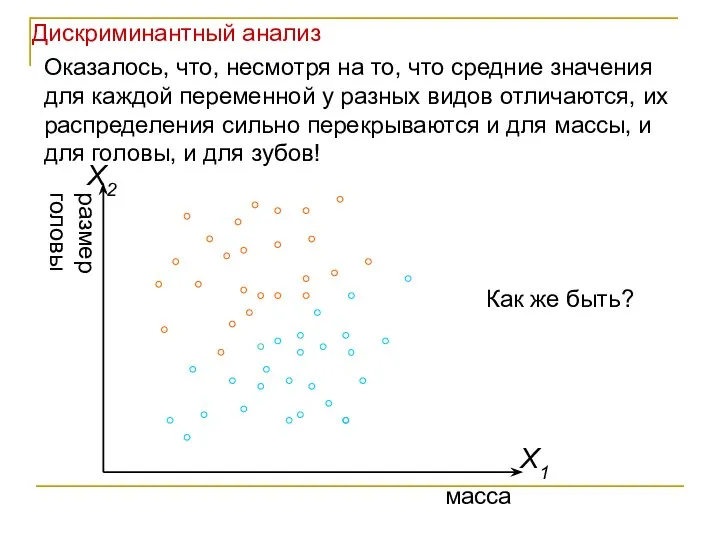
- 7. масса Оказалось, что, несмотря на то, что средние значения для каждой переменной у разных видов отличаются,
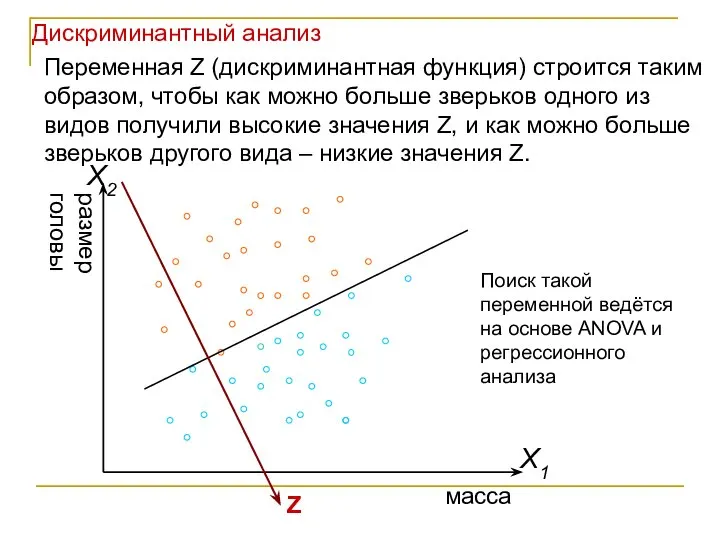
- 8. Z Переменная Z (дискриминантная функция) строится таким образом, чтобы как можно больше зверьков одного из видов
- 9. Создание дискриминантной функции Из выбранных нами переменных (на основе F to enter) рассчитываем новую переменную Z
- 10. Дискриминантный анализ Программа сама выбирает «лучшую» дискриминантную функцию и строит её первой, потом «лучшую» из оставшихся
- 11. Дискриминантный анализ Интерпретация дискриминантных (=канонических) функций: Каждую дискриминантную функцию характеризует Root (канонический корень), и мы можем
- 12. Теперь, когда мы построили такую функцию, мы сможем поймать зверька неизвестного вида, измерить у него X1
- 13. Дискриминантный анализ Теперь можно предсказать, к какой группе относится та или иная особь, и оценить точность
- 14. Итак: Дискриминантная функция рассчитывается только для тех измерений, для которых известно, к какой группе они принадлежат
- 15. Discriminant function analysis
- 16. Выберем переменные для анализа. Выберем пошаговый анализ. Критерии, по которым мы будем включать переменные для построения
- 17. Прежде чем приступить к анализу, посмотрим, есть ли разделение на группы по нашим переменным.
- 18. Предварительный анализ переменных: насколько по ним вообще различаются группы (на основе ANOVA) Wilk’s lambda – статистика,
- 19. Пройдём Шаг 1 и Шаг 2. Можно посмотреть, какие переменные уже включены в анализ. Partial lambda
- 20. Последний Шаг 3: дискриминация между видами значима Partial lambda: Переменная Голова даёт вклад больше всех, а
- 21. Ступень 2: создание дискриминантной функции Предпримем канонический анализ Дискриминантных функций у нас 2 Значимой оказалась только
- 22. Посмотрим, какой вклад внесли переменные в различение групп нашими дискриминантными функциями. Standardized coefficients – коэффициенты для
- 23. Наибольший вклад в первую функцию вносит Голова (она сильнее всего коррелирует с ней). Структура факторов (дискриминантных
- 24. Мы можем посмотреть на разницу средних значений функций между группами. Кошачий лемур сильно отличается от других
- 25. Ступень 3: классификация Функции классификации : мы получаем для них коэффициенты, и можем классифицировать новых лемуров:
- 26. Можно посмотреть, сколько лемуров правильно и неправильно причислено к той или иной группе на основе функций
- 27. На основе дистанций Махаланобиса от каждого измерения до центра группы можно посмотреть, к какому виду тот
- 28. Требования к выборкам для проведения дискриминантного анализа 3. Не должно быть корреляции средних значений и дисперсий
- 29. ФАКТОРНЫЙ АНАЛИЗ Мы много лет изучаем пищевые предпочтения павианов и разработали комплексные оценки того, как они
- 30. Итак, Мы хотим Найти те факторы, которые определяют изменчивость (объясняют действие) большого количества измеренных нами реальных
- 31. Цели факторного анализа в биологии: Преобразование взаимодействия многих переменных во взаимодействие небольшого числа факторов. Уменьшение числа
- 32. Поясняющий пример: Мы изучаем кроликов. Сначала взвешиваем каждого из 100 кроликов на безмене, потом на весах
- 33. Факторный анализ: Анализ главных компонент (principal component analysis); Основная идея: получить факторы, объясняющие как можно больше
- 34. Подразумевается, что наши реально измеренные переменные являются линейными комбинациями этих подлежащих факторов. Факторы (главные компоненты) находят
- 35. Итак, мы изучаем питание павианов. Типов пищи у павианов 10: апельсины, бананы, яблоки, помидоры, огурцы, мясо,
- 36. Principal component analysis (прежде, чем проводить факторный анализ, рекомендуется построить матрицу корреляций: исключить переменные, слишком сильно
- 37. Просмотрим матрицу корреляций: Не должно быть слишком сильно коррелирующих друг с другом переменных (иначе матрица не
- 38. Собственные значения (eigenvalues)– определяют, какую долю общей дисперсии объясняет данный фактор.
- 39. Этот график показывает, что первые два фактора лучше остальных, они объясняют большую часть общей изменчивости (the
- 40. Посмотрим, как полученные факторы связаны с реальными переменными
- 41. Можно выбрать два фактора, расположить в их пространстве переменные; потом повернуть факторы (оси координат) так, чтобы
- 42. Фактор 1 в основном связан с растительной пищей, фактор 2 – с животной. После вращения факторов
- 43. Посмотрим, как исходные переменные расположились в пространстве новых факторов
- 44. Если мы в дальнейшем хотим проводить анализ связи питания павианов с другими переменными, мы можем заменить
- 45. Требования к выборкам для проведения факторного анализа Внутри групп должно быть многомерное нормальное распределение (оценка –
- 46. Если распределение не нормальное, связь переменных нелинейная, выборка небольшая: Многомерное шкалирование (Multidimentional scaling) На основе сходства
- 47. Но если данные более-менее удовлетворяют требованиям факторного анализа, лучше проводить его, т.к.: 1. Факторный анализ -
- 48. Мы наблюдаем поведение молодых сурков. У нас есть 15 переменных, описывающих социальное поведение. Это частоты контактов,
- 49. Данные для анализа должны быть представлены МАТРИЦЕЙ ДИСТАНЦИЙ (как её получать – рассказ дальше) Число измерений
- 50. Программа вращает наши наблюдения в пространстве так, чтобы расстояния между ними в полученной модели лучше всего
- 51. Мы получили итоговую конфигурацию. Посмотрим, насколько она хороша. D-star и D-hat – вычисленные программой дистанции между
- 52. Диаграмма Шепарда покажет, хорошо ли модель согласуется с исходными данными: чем ближе точки к красной линии,
- 53. Наконец, получим значения новых переменных для наших наблюдений и построим картинку, где они расположены в пространстве
- 54. Интерпретация результатов многомерного шкалирования – исключительно на основе картинки, где наблюдения расположены в пространстве новых переменных.
- 55. КЛАСТЕРНЫЙ АНАЛИЗ Это вообще не статистический метод, а чисто описательная математическая процедура группировки и классификации данных.
- 56. Идея анализа – Рассчитываются дистанции между измерениями в пространстве исходных переменных; Евклидовы дистанции; Квадрат евклидова расстояния
- 57. Пример. У нас есть молодые лемуры, которые после расселения заняли дупла в лесу. Известны координаты каждого
- 58. Cluster analysis
- 59. Мы будем рассматривать древовидную кластеризацию; Кластеры будем строить на основе евклидовых дистанций методом ближайшего соседа.
- 60. Можно нарисовать деревья разного вида и посмотреть, на каких уровнях выделяются кластеры Можно получить матрицу дистанций
- 61. Посмотрим, на каких расстояниях какие особи объединяются в кластеры
- 62. По этому графику можно посмотреть, на каком расстоянии происходят скачки в дистанциях присоединения. Если такие скачки
- 63. Дискриминантный анализ Кластерный анализ У нас есть исходно существующие группы. Мы ищем переменные, которые лучше всего
- 65. Скачать презентацию

Дискриминантный анализ
У нас есть зверьки разного возраста, у которых измеряли 20
Дискриминантный анализ
У нас есть зверьки разного возраста, у которых измеряли 20

Для решения таких задач создан
ДИСКРИМИНАНТНЫЙ АНАЛИЗ (discriminant function analysis)
Основная идея:
Мы измерили
Для решения таких задач создан
ДИСКРИМИНАНТНЫЙ АНАЛИЗ (discriminant function analysis)
Основная идея:
Мы измерили

Дискриминантный анализ
Суть анализа:
Очень близок ANOVA. Проверяет, отличаются ли группы на основе
Дискриминантный анализ
Суть анализа:
Очень близок ANOVA. Проверяет, отличаются ли группы на основе

На каждом шаге (для каждой переменной) считается статистика F, т.е. мы
На каждом шаге (для каждой переменной) считается статистика F, т.е. мы

Мы изучаем лемуров на Мадагаскаре.
У нас 3 вида лемуров, мы поймали
Мы изучаем лемуров на Мадагаскаре.
У нас 3 вида лемуров, мы поймали
масса
Оказалось, что, несмотря на то, что средние значения для каждой переменной
масса
Оказалось, что, несмотря на то, что средние значения для каждой переменной
Z
Переменная Z (дискриминантная функция) строится таким образом, чтобы как можно больше
Z
Переменная Z (дискриминантная функция) строится таким образом, чтобы как можно больше

Создание дискриминантной функции
Из выбранных нами переменных (на основе F to enter)
Создание дискриминантной функции
Из выбранных нами переменных (на основе F to enter)

Дискриминантный анализ
Программа сама выбирает «лучшую» дискриминантную функцию и строит её первой,
Дискриминантный анализ
Программа сама выбирает «лучшую» дискриминантную функцию и строит её первой,

Дискриминантный анализ
Интерпретация дискриминантных (=канонических) функций:
Каждую дискриминантную функцию характеризует Root (канонический корень),
Дискриминантный анализ
Интерпретация дискриминантных (=канонических) функций:
Каждую дискриминантную функцию характеризует Root (канонический корень),

Теперь, когда мы построили такую функцию, мы сможем поймать зверька неизвестного
Теперь, когда мы построили такую функцию, мы сможем поймать зверька неизвестного

Дискриминантный анализ
Теперь можно предсказать, к какой группе относится та или иная
Дискриминантный анализ
Теперь можно предсказать, к какой группе относится та или иная

Итак:
Дискриминантная функция рассчитывается только для тех измерений, для которых известно, к
Итак:
Дискриминантная функция рассчитывается только для тех измерений, для которых известно, к
Discriminant function analysis
Discriminant function analysis
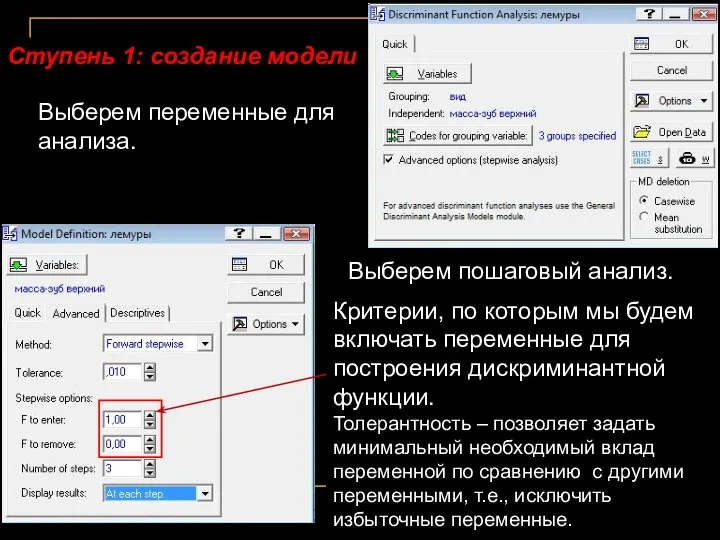
Выберем переменные для анализа.
Выберем пошаговый анализ.
Критерии, по которым мы будем включать
Выберем переменные для анализа.
Выберем пошаговый анализ.
Критерии, по которым мы будем включать
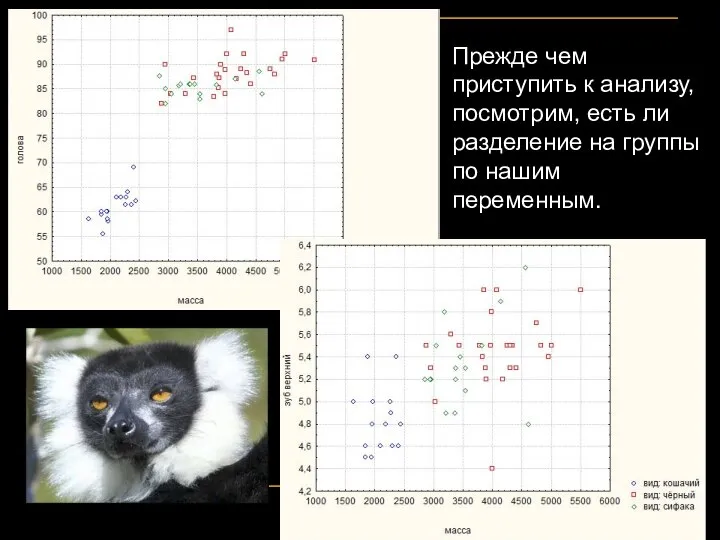
Прежде чем приступить к анализу, посмотрим, есть ли разделение на группы
Прежде чем приступить к анализу, посмотрим, есть ли разделение на группы
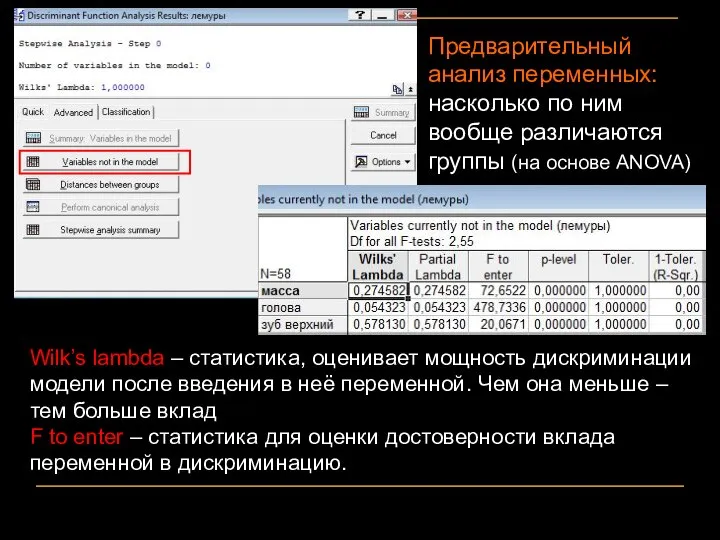
Предварительный анализ переменных: насколько по ним вообще различаются группы (на основе
Предварительный анализ переменных: насколько по ним вообще различаются группы (на основе
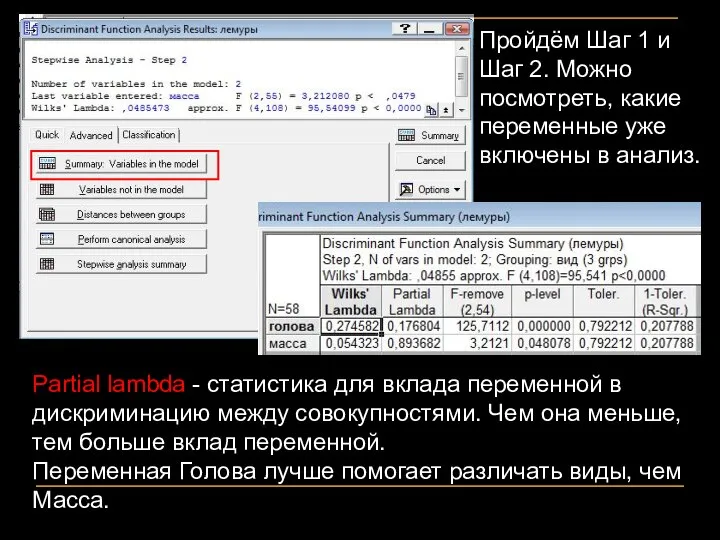
Пройдём Шаг 1 и Шаг 2. Можно посмотреть, какие переменные уже
Пройдём Шаг 1 и Шаг 2. Можно посмотреть, какие переменные уже
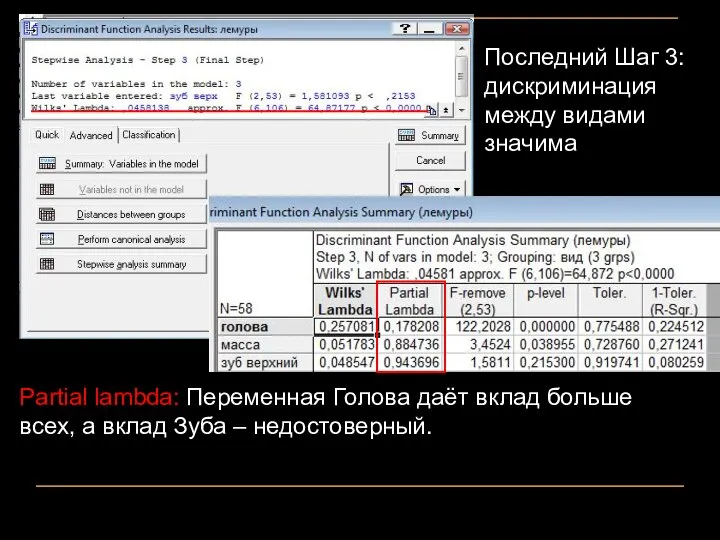
Последний Шаг 3:
дискриминация между видами значима
Partial lambda: Переменная Голова даёт вклад
Последний Шаг 3:
дискриминация между видами значима
Partial lambda: Переменная Голова даёт вклад
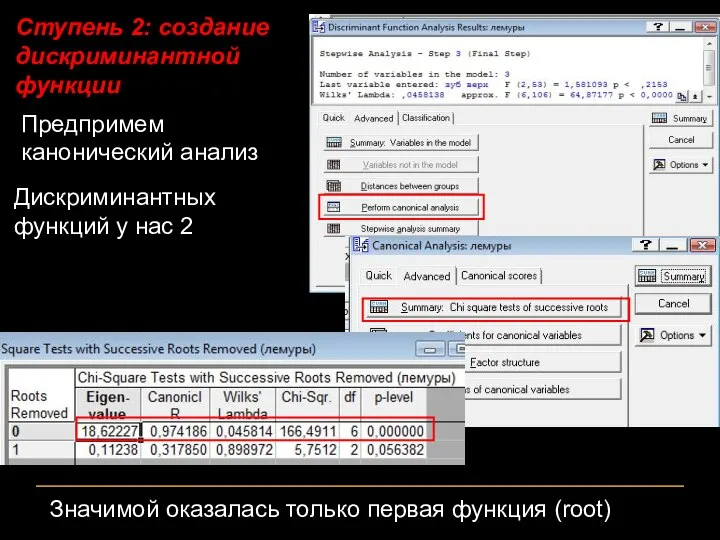
Ступень 2: создание дискриминантной функции
Предпримем канонический анализ
Дискриминантных функций у нас 2
Значимой
Ступень 2: создание дискриминантной функции
Предпримем канонический анализ
Дискриминантных функций у нас 2
Значимой
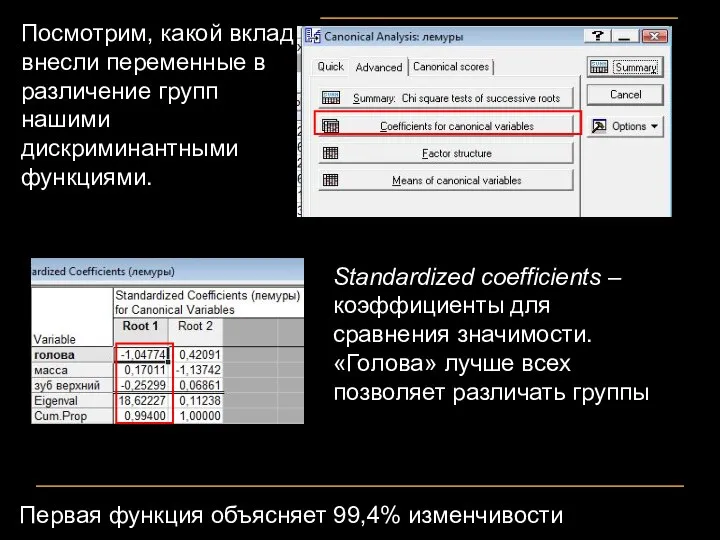
Посмотрим, какой вклад внесли переменные в различение групп нашими дискриминантными функциями.
Standardized
Посмотрим, какой вклад внесли переменные в различение групп нашими дискриминантными функциями.
Standardized
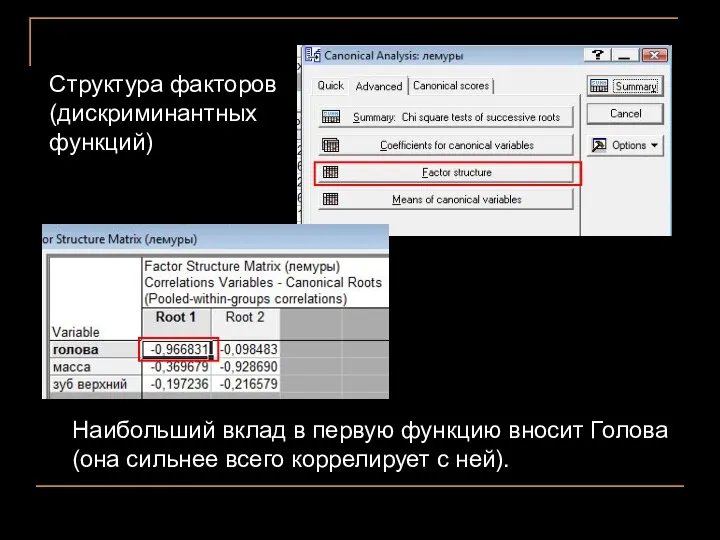
Наибольший вклад в первую функцию вносит Голова (она сильнее всего коррелирует
Наибольший вклад в первую функцию вносит Голова (она сильнее всего коррелирует
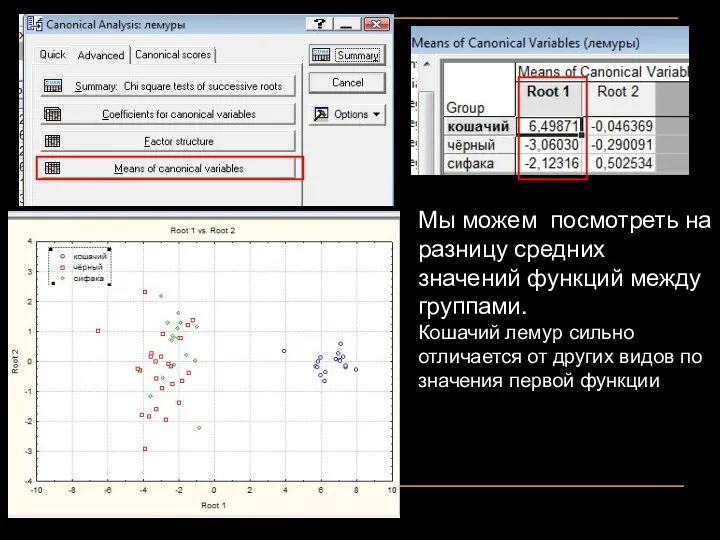
Мы можем посмотреть на разницу средних значений функций между группами.
Кошачий лемур
Мы можем посмотреть на разницу средних значений функций между группами.
Кошачий лемур
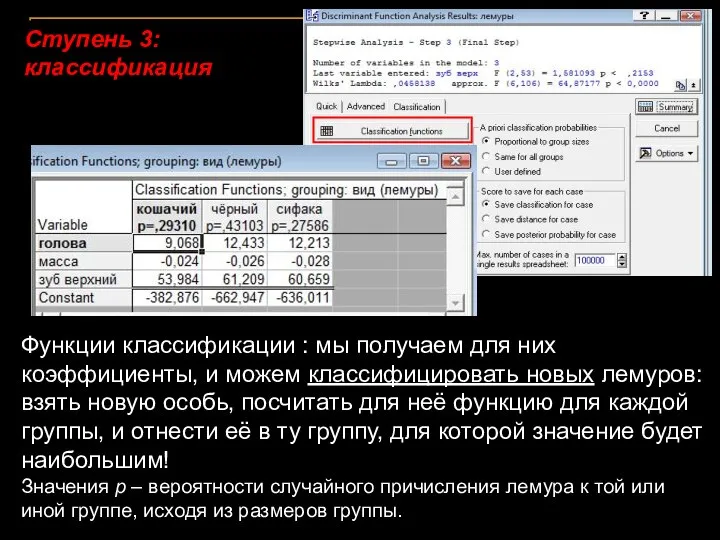
Ступень 3: классификация
Функции классификации : мы получаем для них коэффициенты, и
Ступень 3: классификация
Функции классификации : мы получаем для них коэффициенты, и
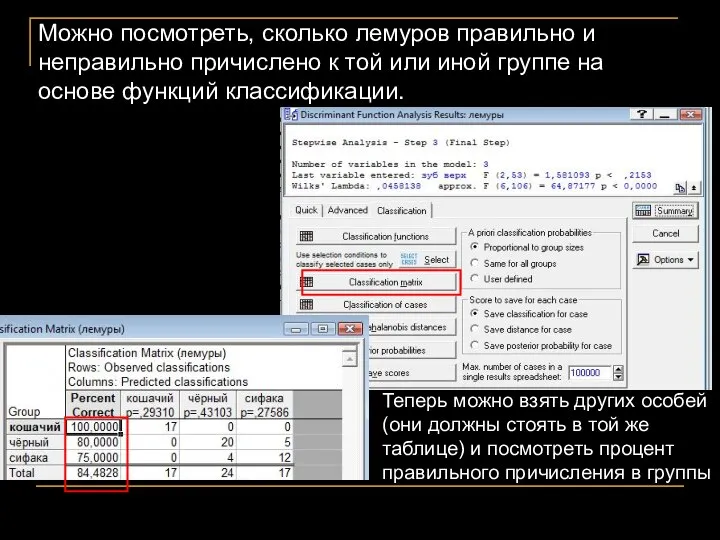
Можно посмотреть, сколько лемуров правильно и неправильно причислено к той или
Можно посмотреть, сколько лемуров правильно и неправильно причислено к той или
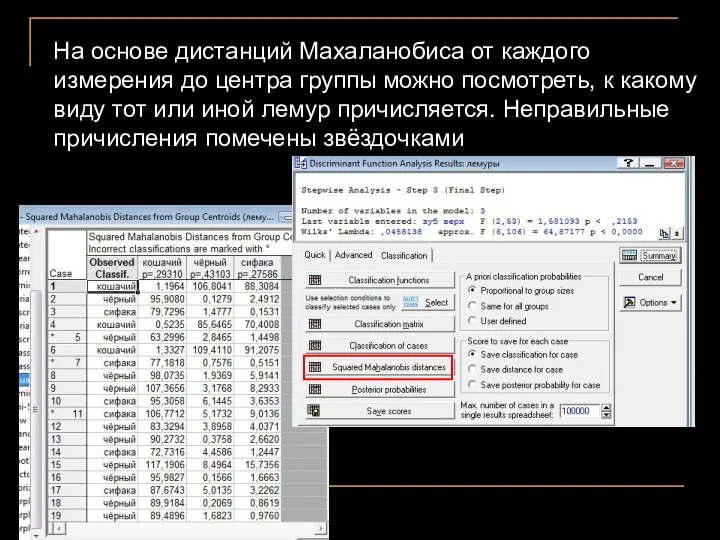
На основе дистанций Махаланобиса от каждого измерения до центра группы можно
На основе дистанций Махаланобиса от каждого измерения до центра группы можно

Требования к выборкам для проведения дискриминантного анализа
3. Не должно быть корреляции
Требования к выборкам для проведения дискриминантного анализа
3. Не должно быть корреляции

ФАКТОРНЫЙ АНАЛИЗ
Мы много лет изучаем пищевые предпочтения павианов и разработали комплексные
ФАКТОРНЫЙ АНАЛИЗ
Мы много лет изучаем пищевые предпочтения павианов и разработали комплексные

Итак,
Мы хотим
Найти те факторы, которые определяют изменчивость (объясняют действие) большого количества
Итак,
Мы хотим
Найти те факторы, которые определяют изменчивость (объясняют действие) большого количества

Цели факторного анализа в биологии:
Преобразование взаимодействия многих переменных во взаимодействие небольшого
Цели факторного анализа в биологии:
Преобразование взаимодействия многих переменных во взаимодействие небольшого

Поясняющий пример:
Мы изучаем кроликов. Сначала взвешиваем каждого из 100 кроликов на
Поясняющий пример:
Мы изучаем кроликов. Сначала взвешиваем каждого из 100 кроликов на

Факторный анализ:
Анализ главных компонент (principal component analysis);
Основная идея: получить факторы, объясняющие
Факторный анализ:
Анализ главных компонент (principal component analysis);
Основная идея: получить факторы, объясняющие
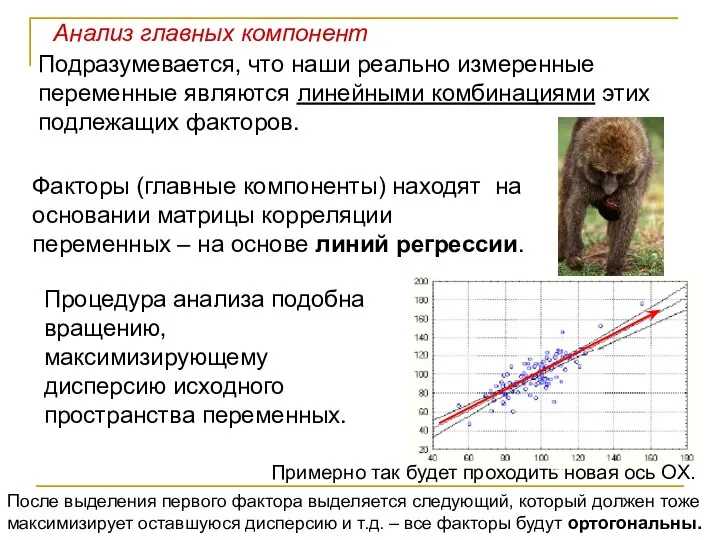
Подразумевается, что наши реально измеренные переменные являются линейными комбинациями этих подлежащих
Подразумевается, что наши реально измеренные переменные являются линейными комбинациями этих подлежащих

Итак, мы изучаем питание павианов. Типов пищи у павианов 10:
апельсины,
бананы,
яблоки,
помидоры,
огурцы,
мясо,
курица,
рыба,
насекомые,
червяки.
Сколько факторов
Итак, мы изучаем питание павианов. Типов пищи у павианов 10:
апельсины,
бананы,
яблоки,
помидоры,
огурцы,
мясо,
курица,
рыба,
насекомые,
червяки.
Сколько факторов
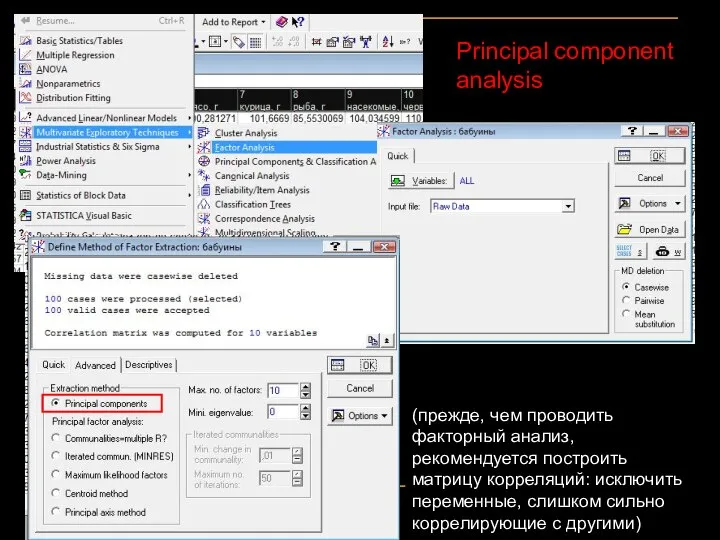
Principal component analysis
(прежде, чем проводить факторный анализ, рекомендуется построить матрицу корреляций:
Principal component analysis
(прежде, чем проводить факторный анализ, рекомендуется построить матрицу корреляций:
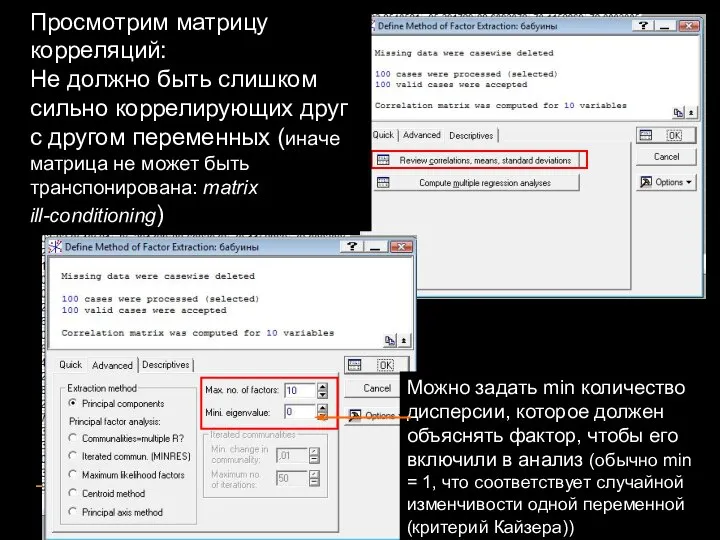
Просмотрим матрицу корреляций:
Не должно быть слишком сильно коррелирующих друг с другом
Просмотрим матрицу корреляций:
Не должно быть слишком сильно коррелирующих друг с другом
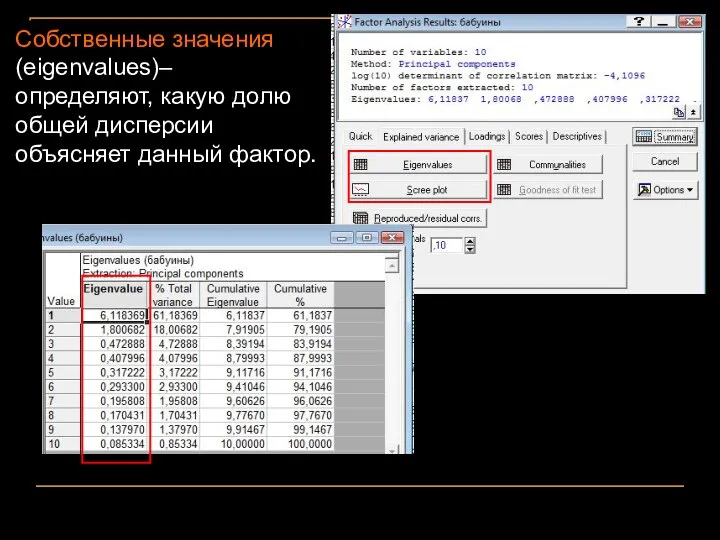
Собственные значения (eigenvalues)– определяют, какую долю общей дисперсии объясняет данный фактор.
Собственные значения (eigenvalues)– определяют, какую долю общей дисперсии объясняет данный фактор.
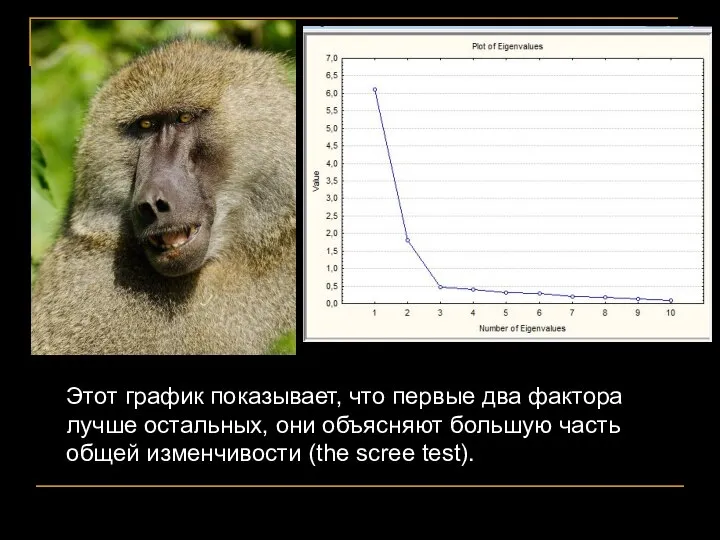
Этот график показывает, что первые два фактора лучше остальных, они объясняют
Этот график показывает, что первые два фактора лучше остальных, они объясняют
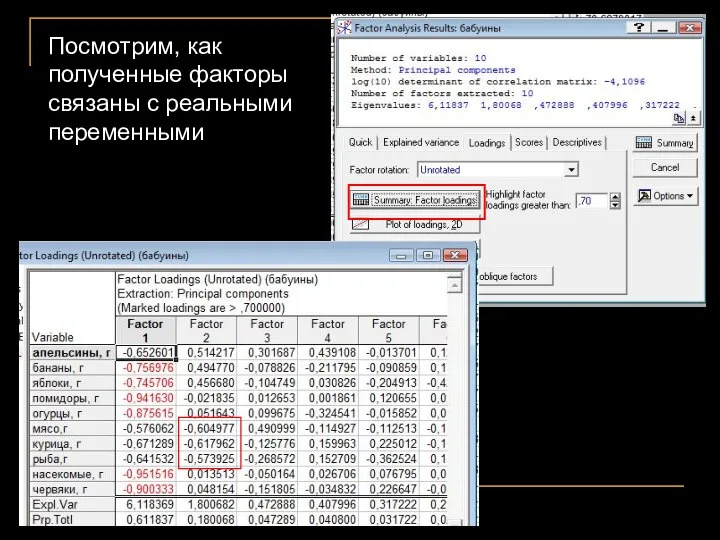
Посмотрим, как полученные факторы связаны с реальными переменными
Посмотрим, как полученные факторы связаны с реальными переменными
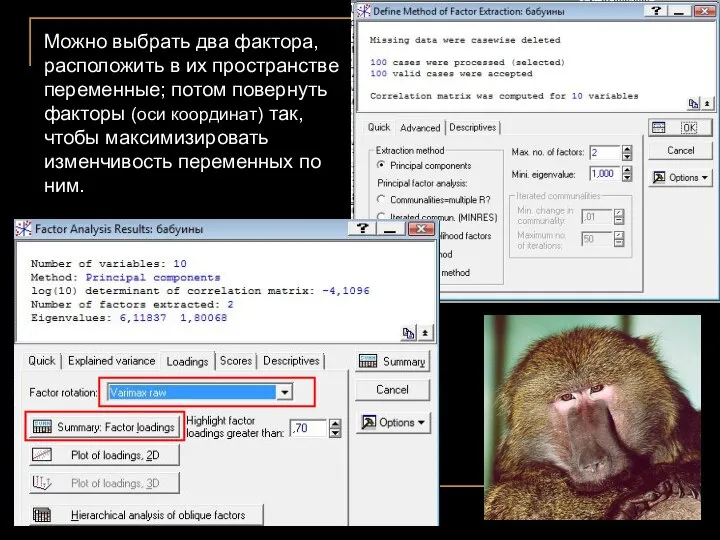
Можно выбрать два фактора, расположить в их пространстве переменные; потом повернуть
Можно выбрать два фактора, расположить в их пространстве переменные; потом повернуть
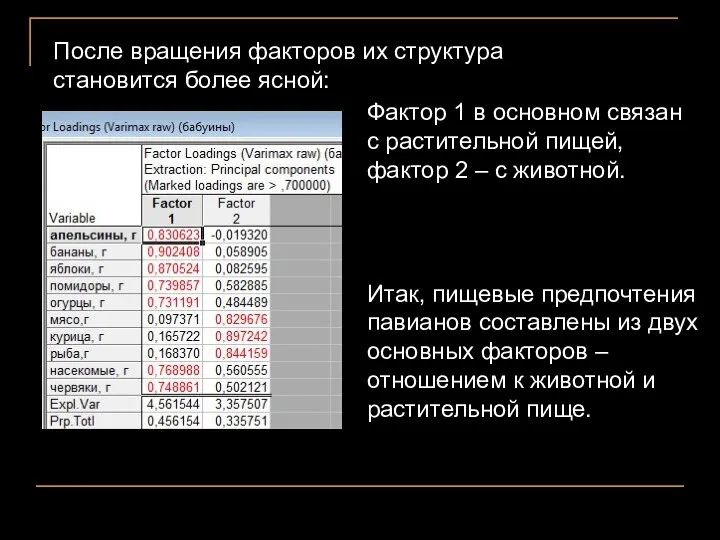
Фактор 1 в основном связан с растительной пищей, фактор 2 –
Фактор 1 в основном связан с растительной пищей, фактор 2 –
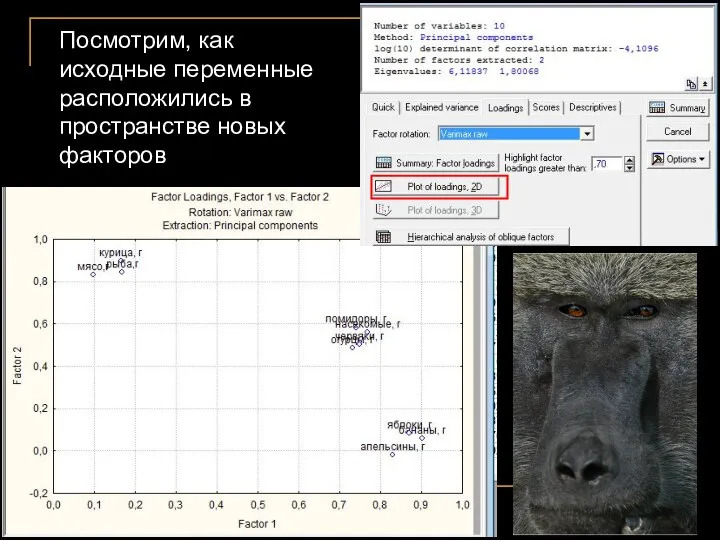
Посмотрим, как исходные переменные расположились в пространстве новых факторов
Посмотрим, как исходные переменные расположились в пространстве новых факторов
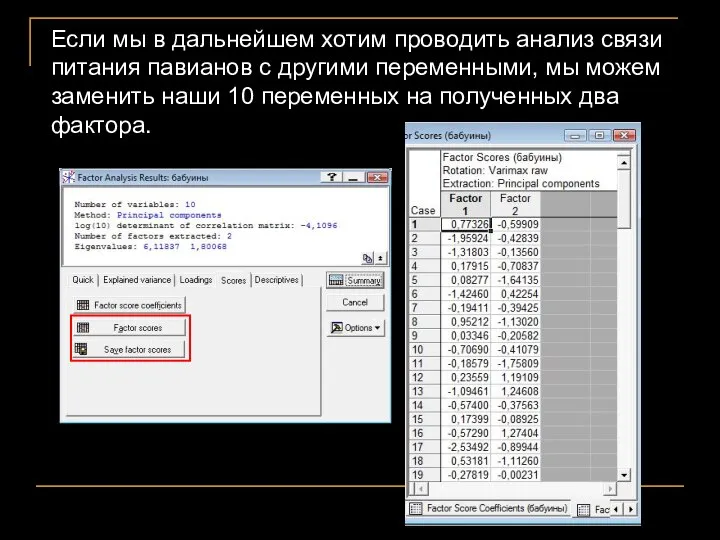
Если мы в дальнейшем хотим проводить анализ связи питания павианов с
Если мы в дальнейшем хотим проводить анализ связи питания павианов с

Требования к выборкам для проведения факторного анализа
Внутри групп должно быть многомерное
Требования к выборкам для проведения факторного анализа
Внутри групп должно быть многомерное

Если распределение не нормальное, связь переменных нелинейная, выборка небольшая:
Многомерное шкалирование
Если распределение не нормальное, связь переменных нелинейная, выборка небольшая:
Многомерное шкалирование

Но если данные более-менее удовлетворяют требованиям факторного анализа, лучше проводить его,
Но если данные более-менее удовлетворяют требованиям факторного анализа, лучше проводить его,

Мы наблюдаем поведение молодых сурков. У нас есть 15 переменных, описывающих
Мы наблюдаем поведение молодых сурков. У нас есть 15 переменных, описывающих
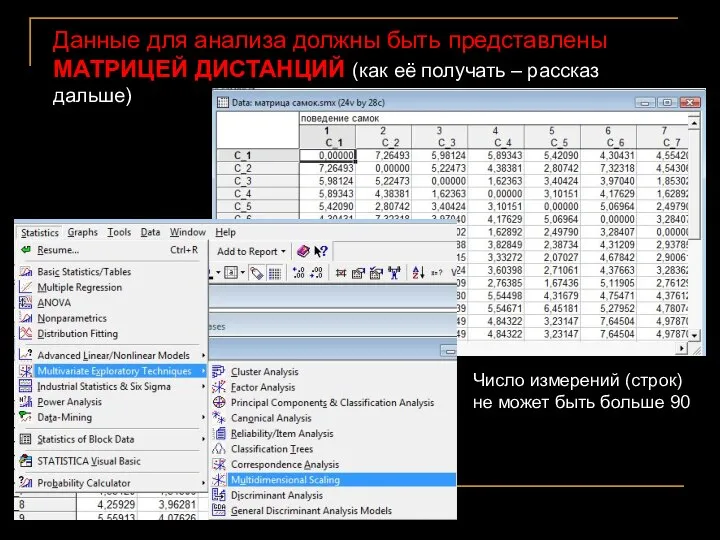
Данные для анализа должны быть представлены МАТРИЦЕЙ ДИСТАНЦИЙ (как её получать
Данные для анализа должны быть представлены МАТРИЦЕЙ ДИСТАНЦИЙ (как её получать
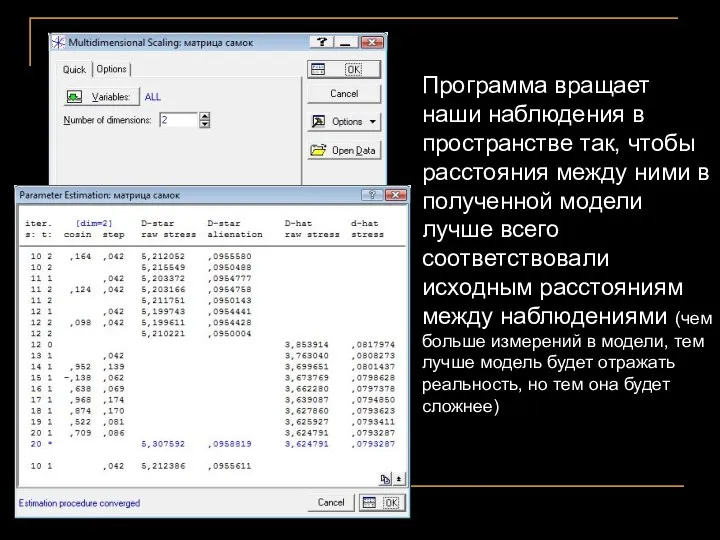
Программа вращает наши наблюдения в пространстве так, чтобы расстояния между ними
Программа вращает наши наблюдения в пространстве так, чтобы расстояния между ними
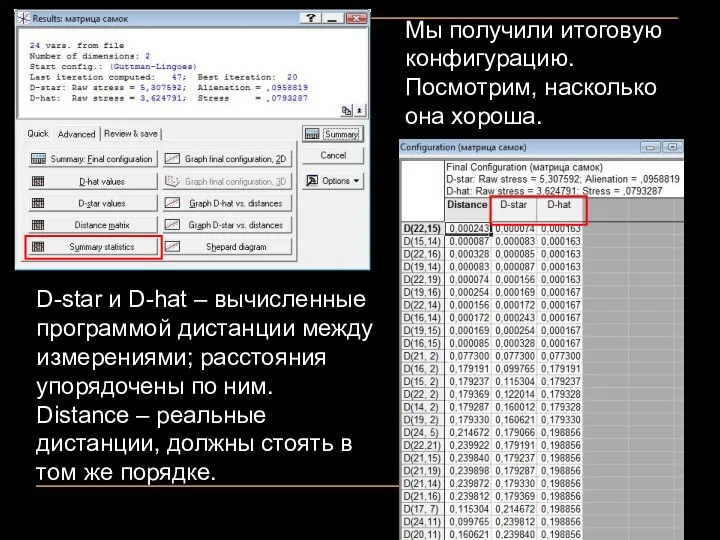
Мы получили итоговую конфигурацию. Посмотрим, насколько она хороша.
D-star и D-hat –
Мы получили итоговую конфигурацию. Посмотрим, насколько она хороша.
D-star и D-hat –
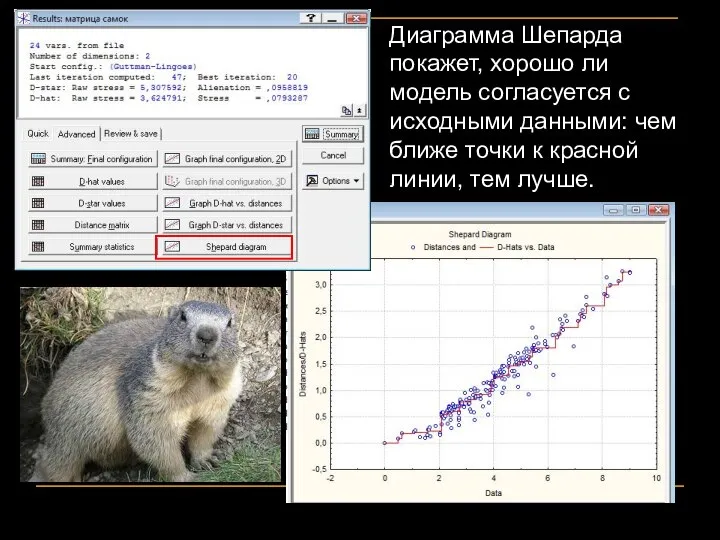
Диаграмма Шепарда покажет, хорошо ли модель согласуется с исходными данными: чем
Диаграмма Шепарда покажет, хорошо ли модель согласуется с исходными данными: чем
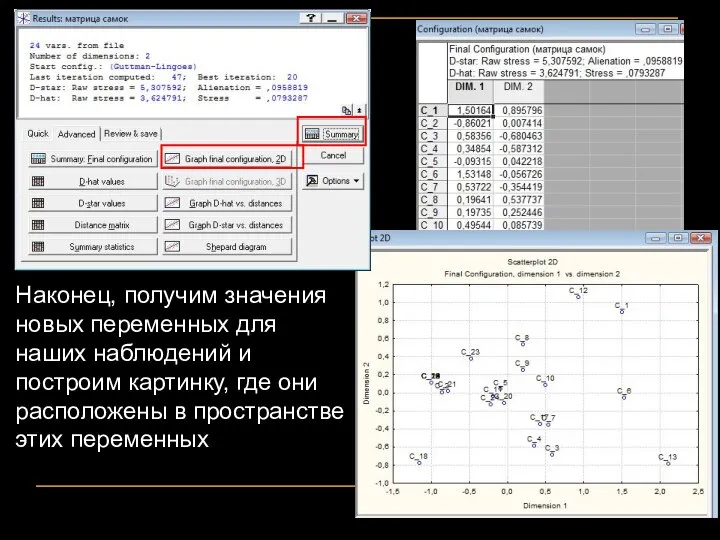
Наконец, получим значения новых переменных для наших наблюдений и построим картинку,
Наконец, получим значения новых переменных для наших наблюдений и построим картинку,

Интерпретация результатов многомерного шкалирования –
исключительно на основе картинки, где наблюдения
Интерпретация результатов многомерного шкалирования –
исключительно на основе картинки, где наблюдения

КЛАСТЕРНЫЙ АНАЛИЗ
Это вообще не статистический метод, а чисто описательная математическая процедура
КЛАСТЕРНЫЙ АНАЛИЗ
Это вообще не статистический метод, а чисто описательная математическая процедура

Идея анализа –
Рассчитываются дистанции между измерениями в пространстве исходных переменных;
Евклидовы
Идея анализа –
Рассчитываются дистанции между измерениями в пространстве исходных переменных;
Евклидовы

Пример.
У нас есть молодые лемуры, которые после расселения заняли дупла в
Пример.
У нас есть молодые лемуры, которые после расселения заняли дупла в
Cluster analysis
Cluster analysis
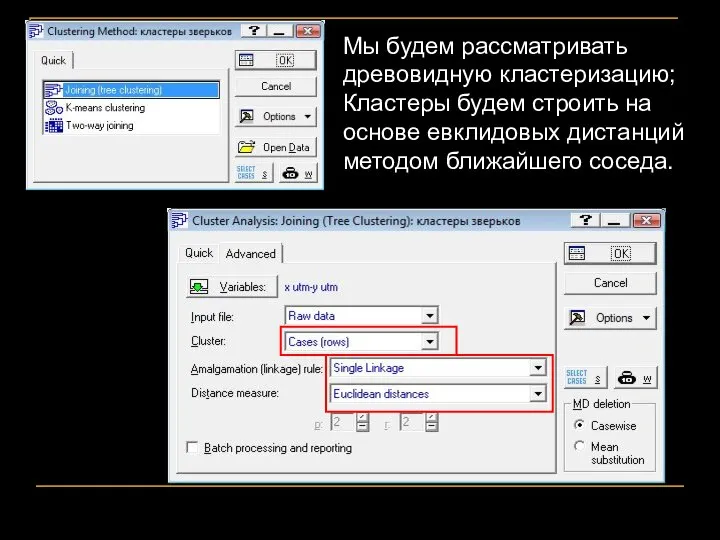
Мы будем рассматривать древовидную кластеризацию;
Кластеры будем строить на основе евклидовых дистанций
Мы будем рассматривать древовидную кластеризацию;
Кластеры будем строить на основе евклидовых дистанций
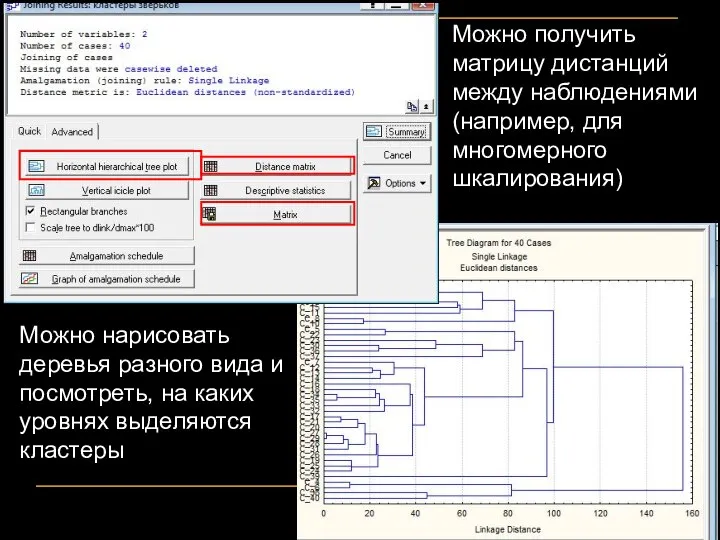
Можно нарисовать деревья разного вида и посмотреть, на каких уровнях выделяются
Можно нарисовать деревья разного вида и посмотреть, на каких уровнях выделяются
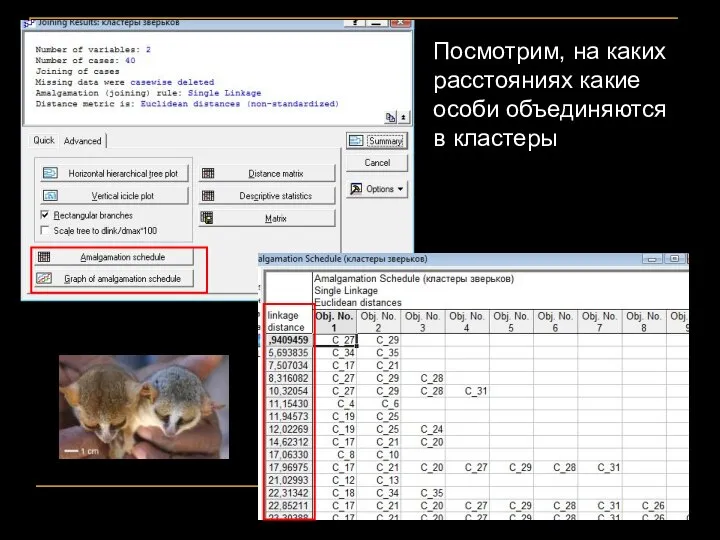
Посмотрим, на каких расстояниях какие особи объединяются в кластеры
Посмотрим, на каких расстояниях какие особи объединяются в кластеры
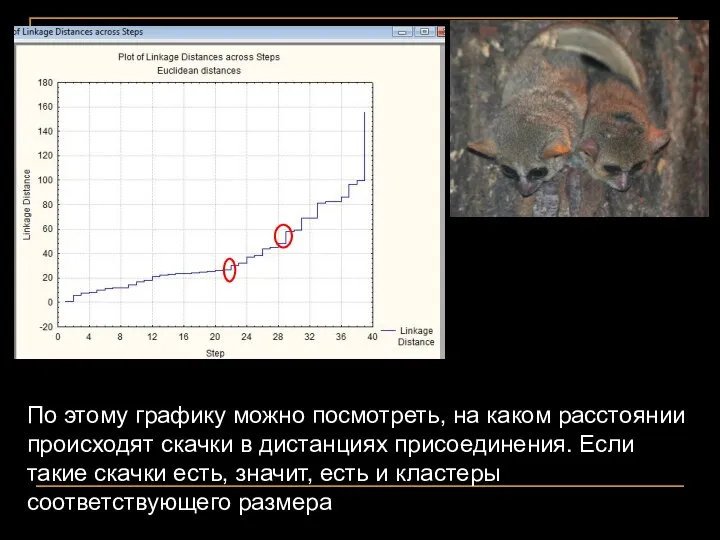
По этому графику можно посмотреть, на каком расстоянии происходят скачки в
По этому графику можно посмотреть, на каком расстоянии происходят скачки в
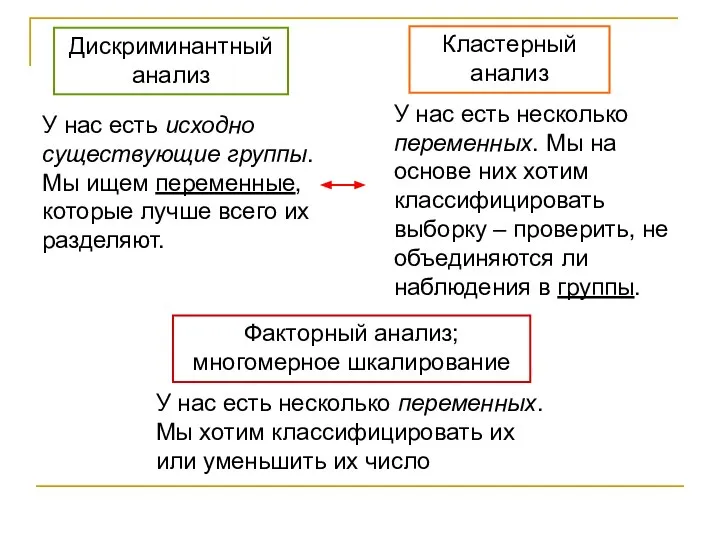
Дискриминантный анализ
Кластерный анализ
У нас есть исходно существующие группы. Мы ищем переменные,
Дискриминантный анализ
Кластерный анализ
У нас есть исходно существующие группы. Мы ищем переменные,
 Урок математики по теме «Таблица сложения» 1 класс А Учитель :Остапенко Л.Н.
Урок математики по теме «Таблица сложения» 1 класс А Учитель :Остапенко Л.Н. Первое знакомство с понятием вероятность. Урок 146
Первое знакомство с понятием вероятность. Урок 146 Презентация по математике "Треугольники" - скачать
Презентация по математике "Треугольники" - скачать  Свойства степенных рядов. (Лекция 2.18)
Свойства степенных рядов. (Лекция 2.18) Презентация по математике "Сложение с числом ноль" - скачать
Презентация по математике "Сложение с числом ноль" - скачать  Нестандартные способы математических вычислений
Нестандартные способы математических вычислений Решение логической задачи (1 класс)
Решение логической задачи (1 класс) Презентация на тему АЛГОРИТМ ЕВКЛИДА
Презентация на тему АЛГОРИТМ ЕВКЛИДА  Признаки равенства треугольников. Тест
Признаки равенства треугольников. Тест Геометрический смысл производной
Геометрический смысл производной Пирамида. Правильная и усеченная пирамида
Пирамида. Правильная и усеченная пирамида Мониторинг качества знаний по математике 4 класс
Мониторинг качества знаний по математике 4 класс Свойства квадратных корней
Свойства квадратных корней Линейное уравнение с одной переменной
Линейное уравнение с одной переменной Концепция риска. Оценка безопасности
Концепция риска. Оценка безопасности Элементы дифференциального исчисления. Производые. Исследование (лекция 2)
Элементы дифференциального исчисления. Производые. Исследование (лекция 2) Учебный проект по математике «Морской пейзаж» Муниципальное общеобразовательное учреждение «Лермонтовская средняя общеобразо
Учебный проект по математике «Морской пейзаж» Муниципальное общеобразовательное учреждение «Лермонтовская средняя общеобразо Сфера
Сфера Период математического маятника
Период математического маятника Презентация урока математики в 5 классе по теме: «Действия с десятичными дробями» С. Бабынино МКОУ «СОШ№1» Нагаевой А.Н.
Презентация урока математики в 5 классе по теме: «Действия с десятичными дробями» С. Бабынино МКОУ «СОШ№1» Нагаевой А.Н.  Конечные автоматы
Конечные автоматы Искусственные и нечеткие нейронные сети
Искусственные и нечеткие нейронные сети Решение иррациональных неравенств
Решение иррациональных неравенств Parallelepiped rectangular solid cube. Some special prisms
Parallelepiped rectangular solid cube. Some special prisms Тема 5. Вступ до математичного аналізу. Лекція №11. Неперервність функції. Визначні границі
Тема 5. Вступ до математичного аналізу. Лекція №11. Неперервність функції. Визначні границі Задачи на дроби
Задачи на дроби Объём прямоугольного параллелепипеда
Объём прямоугольного параллелепипеда Числовые выражения
Числовые выражения