-
Занятие 9 Основы многомерных методов анализа. Факторный анализ.

Содержание
- 2. Методы многомерного анализа (multivariate analyses) Предназначены для анализа многомерных данных Много независимых переменных – Многофакторная ANOVA
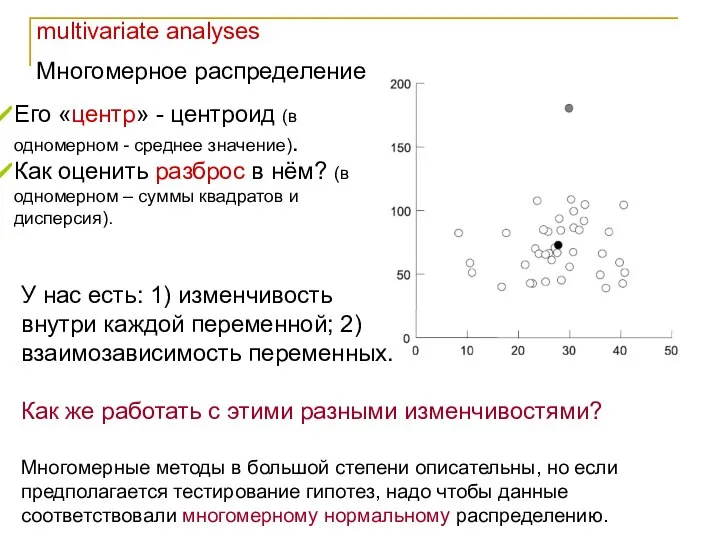
- 3. multivariate analyses Многомерное распределение Многомерные методы в большой степени описательны, но если предполагается тестирование гипотез, надо
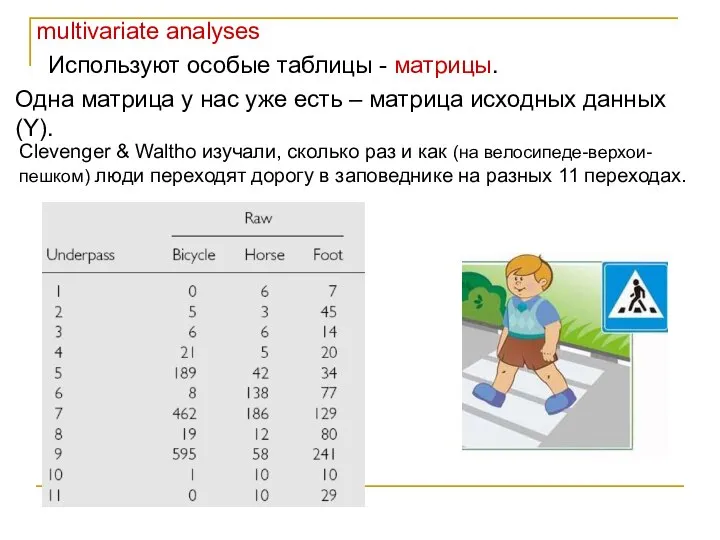
- 4. multivariate analyses Используют особые таблицы - матрицы. Одна матрица у нас уже есть – матрица исходных
- 5. multivariate analyses Матрица (p x p) с суммами квадратов на диагонали (sums-of-squares-and-cross-products, SSCP) Матрица дисперсий и
- 6. multivariate analyses Матрица корреляций (correlation matrix, R) – получится, если в предыдущей матрице каждый элемент поделить
- 7. multivariate analyses Фундаментальная процедура в многомерном анализе – получение линейных комбинаций исходных переменных, так, что общая
- 8. multivariate analyses Новые переменные формируют так, чтобы первая объясняла максимум изменчивости исходных переменных, вторая – максимум
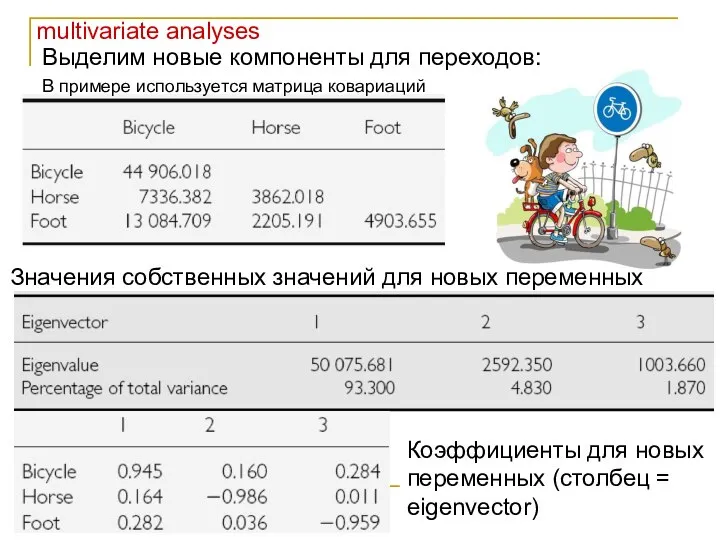
- 9. multivariate analyses Выделим новые компоненты для переходов: В примере используется матрица ковариаций Значения собственных значений для
- 10. multivariate analyses Теперь можно для каждого конкретного перехода посчитать значения новых переменных = компонент. И, например,
- 11. multivariate analyses Матрица «дистанций» меду объектами (dissimilarity matrix):
- 12. multivariate analyses Есть много показателей «дистанции» между объектами (самый очевидный – евклидовы расстояния). Дистанции можно посчитать
- 13. multivariate analyses Подготовка данных для многомерного анализа Трансформация данных: нормализует распределения и делает отношения между переменными
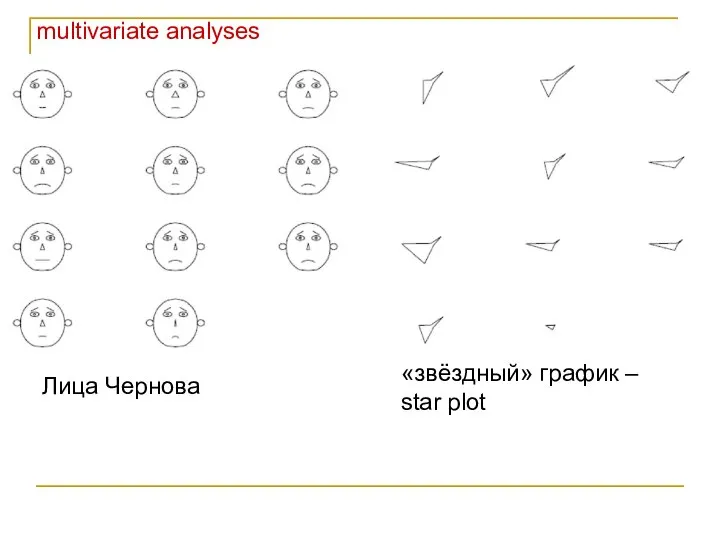
- 14. multivariate analyses Лица Чернова «звёздный» график – star plot
- 15. ФАКТОРНЫЙ АНАЛИЗ У нас в руках измерения большого числа переменных для выборки объектов. Наши цели: Уменьшить
- 16. Анализ главных компонент (principal component analysis, PCA) Factor analysis У нас есть n объектов и p
- 17. Factor analysis Этап 0. Подготовка данных к анализу. Проверка распределений на соответствие нормальному; Трансформация данных (напр.,
- 18. Factor analysis Этап 3. получение factor loadings Это показатели корреляции (Пирсона) компонент с каждой из исходных
- 19. Factor analysis Несколько слов о компонентах (факторах): В многомерном пространстве первая компонента располагается вдоль наибольшей дисперсии,
- 20. Вращение компонент (факторов) Factor analysis Выбранные нами факторы (их мало) поворачивают для получения более чёткой структуры
- 21. Мы изучаем пищевые предпочтения павианов и разработали комплексные оценки привлекательности разных типов пищи для каждой особи.
- 22. Итак, Мы хотим Найти те факторы, которые определяют изменчивость (объясняют действие) большого количества измеренных нами реальных
- 23. Поясняющий пример: Мы изучаем кроликов. Сначала взвешиваем каждого из 100 кроликов на безмене, потом на весах
- 24. Подразумевается, что наши реально измеренные переменные являются линейными комбинациями этих подлежащих факторов. Примерно так будет проходить
- 25. Итак, мы изучаем питание павианов. Типов пищи у павианов 10: апельсины, бананы, яблоки, помидоры, огурцы, мясо,
- 26. Principal component analysis (прежде, чем проводить факторный анализ, рекомендуется построить матрицу корреляций: исключить переменные, слишком сильно
- 27. Просмотрим матрицу корреляций: Не должно быть слишком сильно коррелирующих друг с другом переменных (иначе матрица не
- 28. Собственные значения (eigenvalues)– определяют, какую долю общей дисперсии объясняет данный фактор.
- 29. Этот график показывает, что первые два фактора лучше остальных, они объясняют большую часть общей изменчивости (the
- 30. Посмотрим, как полученные факторы связаны с реальными переменными
- 31. оставим две компоненты и проведём вращение, чтобы улучшить их структуру.
- 32. Фактор 1 в основном связан с растительной пищей, фактор 2 – с животной. После вращения факторов
- 33. Посмотрим, как исходные переменные расположились в пространстве новых факторов
- 34. Если мы в дальнейшем хотим проводить анализ связи питания павианов с другими переменными, мы можем заменить
- 35. Требования к выборкам для проведения факторного анализа Внутри групп должно быть многомерное нормальное распределение (оценка –
- 36. Связь с MANOVA и регрессионным анализом. Factor analysis Если мы на самом деле хотим сравнить группы
- 37. Principal factor analysis – если PCA генерирует компоненты, объясняющие изменчивость исходных переменных, то PFA генерирует common
- 38. Redundancy analysis – усложнённая версия Canonical correlation analysis, предсказывает линейную комбинацию зависимых переменных из комбинации независимых.
- 40. Скачать презентацию

Методы многомерного анализа (multivariate analyses)
Предназначены для анализа многомерных данных
Много независимых переменных
Методы многомерного анализа (multivariate analyses)
Предназначены для анализа многомерных данных
Много независимых переменных
multivariate analyses
Многомерное распределение
Многомерные методы в большой степени описательны, но если предполагается
multivariate analyses
Многомерное распределение
Многомерные методы в большой степени описательны, но если предполагается
multivariate analyses
Используют особые таблицы - матрицы.
Одна матрица у нас уже есть
multivariate analyses
Используют особые таблицы - матрицы.
Одна матрица у нас уже есть

multivariate analyses
Матрица (p x p) с суммами квадратов на диагонали (sums-of-squares-and-cross-products,
multivariate analyses
Матрица (p x p) с суммами квадратов на диагонали (sums-of-squares-and-cross-products,

multivariate analyses
Матрица корреляций (correlation matrix, R) – получится, если в предыдущей
multivariate analyses
Матрица корреляций (correlation matrix, R) – получится, если в предыдущей

multivariate analyses
Фундаментальная процедура в многомерном анализе – получение линейных комбинаций исходных
multivariate analyses
Фундаментальная процедура в многомерном анализе – получение линейных комбинаций исходных

multivariate analyses
Новые переменные формируют так, чтобы первая объясняла максимум изменчивости исходных
multivariate analyses
Новые переменные формируют так, чтобы первая объясняла максимум изменчивости исходных
multivariate analyses
Выделим новые компоненты для переходов:
В примере используется матрица ковариаций
Значения собственных
multivariate analyses
Выделим новые компоненты для переходов:
В примере используется матрица ковариаций
Значения собственных

multivariate analyses
Теперь можно для каждого конкретного перехода посчитать значения новых переменных
multivariate analyses
Теперь можно для каждого конкретного перехода посчитать значения новых переменных

multivariate analyses
Матрица «дистанций» меду объектами (dissimilarity matrix):
multivariate analyses
Матрица «дистанций» меду объектами (dissimilarity matrix):

multivariate analyses
Есть много показателей «дистанции» между объектами (самый очевидный – евклидовы
multivariate analyses
Есть много показателей «дистанции» между объектами (самый очевидный – евклидовы

multivariate analyses
Подготовка данных для многомерного анализа
Трансформация данных: нормализует распределения и делает
multivariate analyses
Подготовка данных для многомерного анализа
Трансформация данных: нормализует распределения и делает
multivariate analyses
Лица Чернова
«звёздный» график – star plot
multivariate analyses
Лица Чернова
«звёздный» график – star plot

ФАКТОРНЫЙ АНАЛИЗ
У нас в руках измерения большого числа переменных для
выборки
ФАКТОРНЫЙ АНАЛИЗ
У нас в руках измерения большого числа переменных для
выборки

Анализ главных компонент
(principal component analysis, PCA)
Factor analysis
У нас есть n объектов
Анализ главных компонент
(principal component analysis, PCA)
Factor analysis
У нас есть n объектов

Factor analysis
Этап 0. Подготовка данных к анализу.
Проверка распределений на соответствие нормальному;
Трансформация
Factor analysis
Этап 0. Подготовка данных к анализу.
Проверка распределений на соответствие нормальному;
Трансформация

Factor analysis
Этап 3. получение factor loadings
Это показатели корреляции (Пирсона) компонент с
Factor analysis
Этап 3. получение factor loadings
Это показатели корреляции (Пирсона) компонент с

Factor analysis
Несколько слов о компонентах (факторах):
В многомерном пространстве первая компонента располагается
Factor analysis
Несколько слов о компонентах (факторах):
В многомерном пространстве первая компонента располагается

Вращение компонент (факторов)
Factor analysis
Выбранные нами факторы (их мало) поворачивают для получения
Вращение компонент (факторов)
Factor analysis
Выбранные нами факторы (их мало) поворачивают для получения

Мы изучаем пищевые предпочтения павианов и разработали комплексные оценки привлекательности разных
Мы изучаем пищевые предпочтения павианов и разработали комплексные оценки привлекательности разных

Итак,
Мы хотим
Найти те факторы, которые определяют изменчивость (объясняют действие) большого количества
Итак,
Мы хотим
Найти те факторы, которые определяют изменчивость (объясняют действие) большого количества

Поясняющий пример:
Мы изучаем кроликов. Сначала взвешиваем каждого из 100 кроликов на
Поясняющий пример:
Мы изучаем кроликов. Сначала взвешиваем каждого из 100 кроликов на
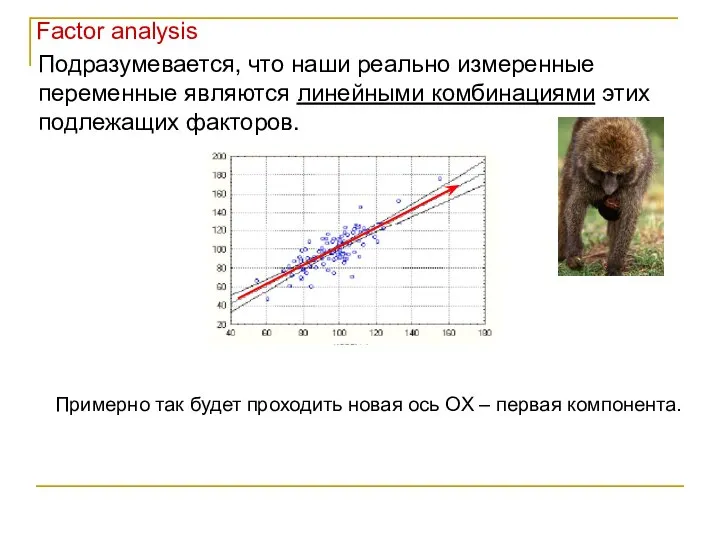
Подразумевается, что наши реально измеренные переменные являются линейными комбинациями этих подлежащих
Подразумевается, что наши реально измеренные переменные являются линейными комбинациями этих подлежащих

Итак, мы изучаем питание павианов. Типов пищи у павианов 10:
апельсины,
бананы,
яблоки,
помидоры,
огурцы,
мясо,
курица,
рыба,
насекомые,
червяки.
Мы измеряем
Итак, мы изучаем питание павианов. Типов пищи у павианов 10:
апельсины,
бананы,
яблоки,
помидоры,
огурцы,
мясо,
курица,
рыба,
насекомые,
червяки.
Мы измеряем
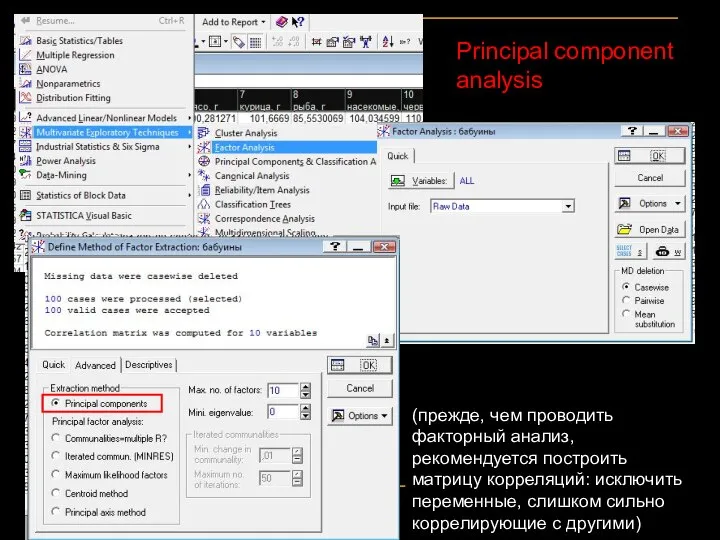
Principal component analysis
(прежде, чем проводить факторный анализ, рекомендуется построить матрицу корреляций:
Principal component analysis
(прежде, чем проводить факторный анализ, рекомендуется построить матрицу корреляций:
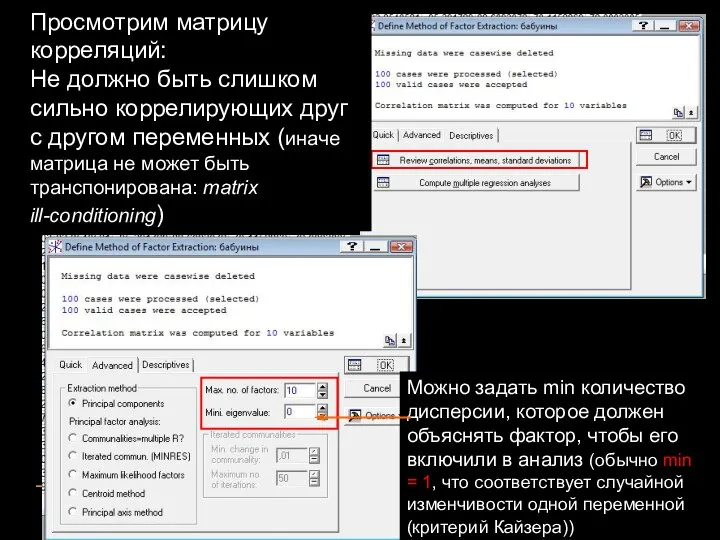
Просмотрим матрицу корреляций:
Не должно быть слишком сильно коррелирующих друг с другом
Просмотрим матрицу корреляций:
Не должно быть слишком сильно коррелирующих друг с другом
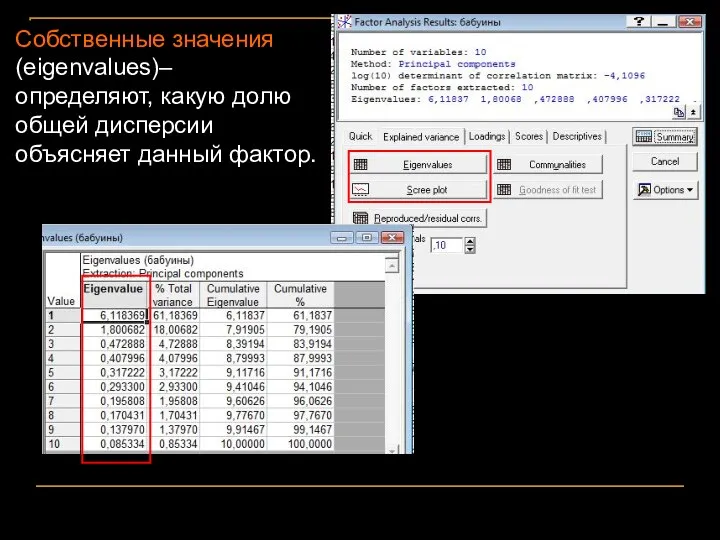
Собственные значения (eigenvalues)– определяют, какую долю общей дисперсии объясняет данный фактор.
Собственные значения (eigenvalues)– определяют, какую долю общей дисперсии объясняет данный фактор.
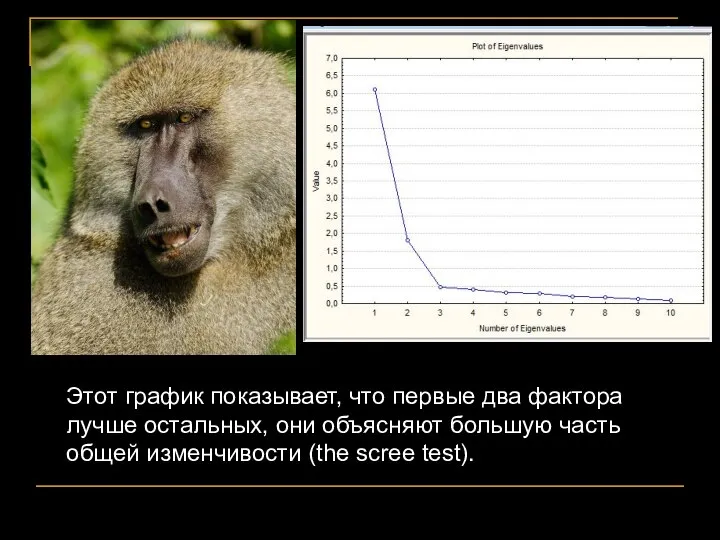
Этот график показывает, что первые два фактора лучше остальных, они объясняют
Этот график показывает, что первые два фактора лучше остальных, они объясняют
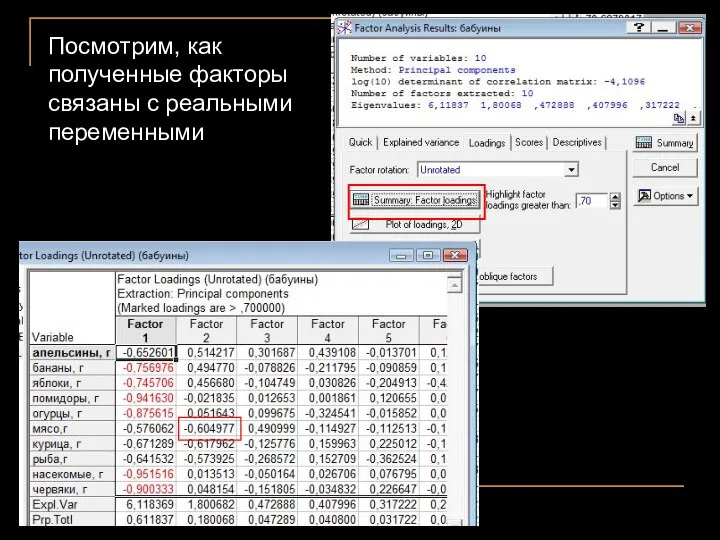
Посмотрим, как полученные факторы связаны с реальными переменными
Посмотрим, как полученные факторы связаны с реальными переменными
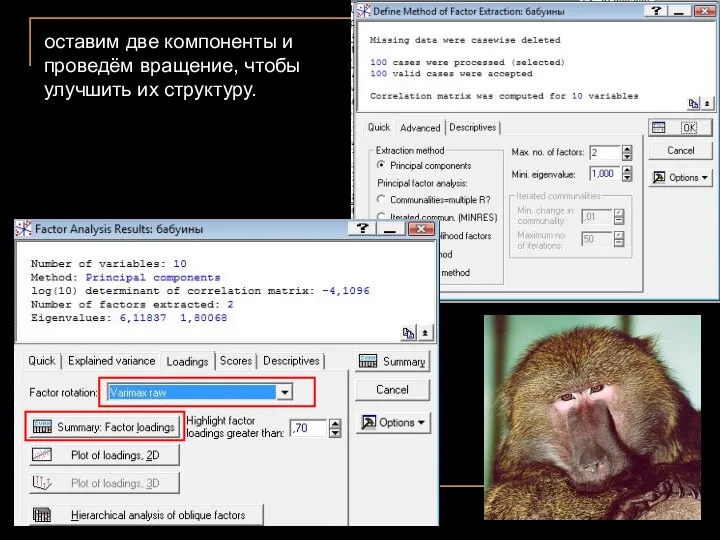
оставим две компоненты и проведём вращение, чтобы улучшить их структуру.
оставим две компоненты и проведём вращение, чтобы улучшить их структуру.
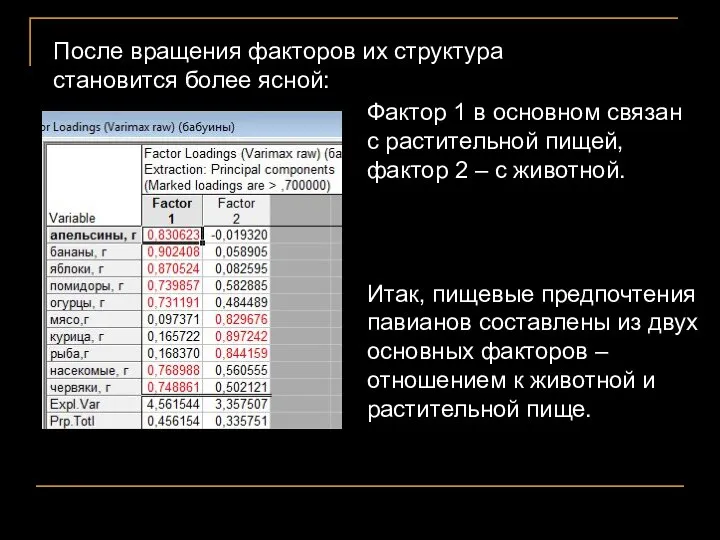
Фактор 1 в основном связан с растительной пищей, фактор 2 –
Фактор 1 в основном связан с растительной пищей, фактор 2 –
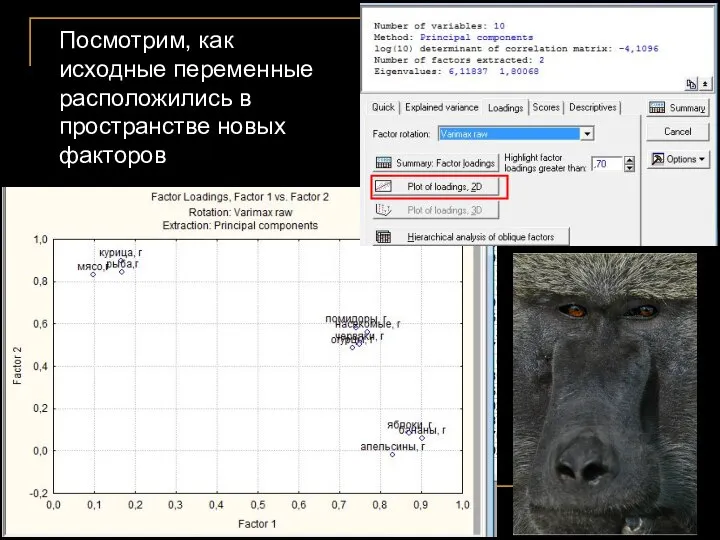
Посмотрим, как исходные переменные расположились в пространстве новых факторов
Посмотрим, как исходные переменные расположились в пространстве новых факторов
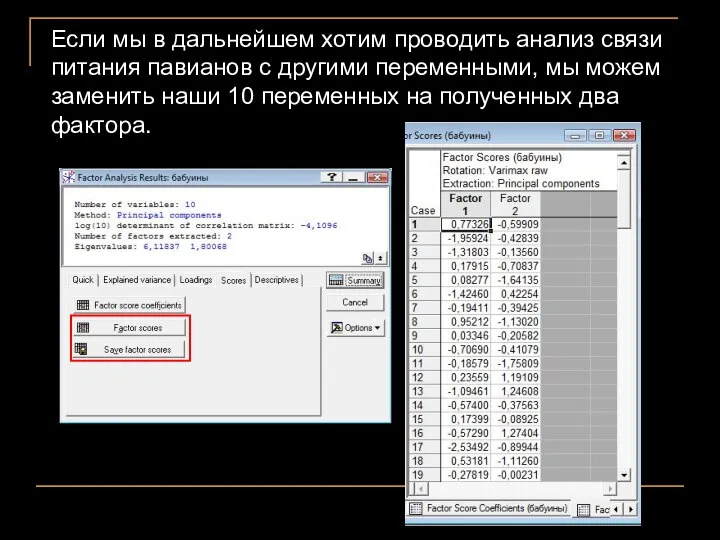
Если мы в дальнейшем хотим проводить анализ связи питания павианов с
Если мы в дальнейшем хотим проводить анализ связи питания павианов с

Требования к выборкам для проведения факторного анализа
Внутри групп должно быть многомерное
Требования к выборкам для проведения факторного анализа
Внутри групп должно быть многомерное

Связь с MANOVA и регрессионным анализом.
Factor analysis
Если мы на самом деле
Связь с MANOVA и регрессионным анализом.
Factor analysis
Если мы на самом деле

Principal factor analysis – если PCA генерирует компоненты, объясняющие изменчивость исходных
Principal factor analysis – если PCA генерирует компоненты, объясняющие изменчивость исходных

Redundancy analysis – усложнённая версия Canonical correlation analysis, предсказывает линейную комбинацию
Redundancy analysis – усложнённая версия Canonical correlation analysis, предсказывает линейную комбинацию
 Ознаки паралельності прямих
Ознаки паралельності прямих Скачать презентацию Умножение
Скачать презентацию Умножение  Презентация по математике "Даты и судьбы" - скачать
Презентация по математике "Даты и судьбы" - скачать  Урок-конференция. Число π
Урок-конференция. Число π «Нахождение числа по его дроби»
«Нахождение числа по его дроби» Математическая мозаика
Математическая мозаика Решение задач, возникающих в реальной жизни, с использованием теоретико-множественного подхода
Решение задач, возникающих в реальной жизни, с использованием теоретико-множественного подхода Позитивное мышление. Методы рационализации неравенств
Позитивное мышление. Методы рационализации неравенств Умножение десятичных дробей. 5 класс
Умножение десятичных дробей. 5 класс Аксиомы параллельности прямых
Аксиомы параллельности прямых Длина окружности. Площадь круга. Шар. Лабораторная работа
Длина окружности. Площадь круга. Шар. Лабораторная работа Производная. Основные теоремы о производных. Формулы дифференцирования функций. (Лекция 5)
Производная. Основные теоремы о производных. Формулы дифференцирования функций. (Лекция 5) Золотое сечение
Золотое сечение Программа элективного курса по математике «Математика в задачах»
Программа элективного курса по математике «Математика в задачах» Тригонометрические ряды Фурье
Тригонометрические ряды Фурье Алгебраические выражения и их преобразование. 9 класс
Алгебраические выражения и их преобразование. 9 класс Числовые, функциональные и степенные ряды
Числовые, функциональные и степенные ряды Числовые и функциональные ряды
Числовые и функциональные ряды «Звёздная математика». Устный счёт. 1 класс
«Звёздная математика». Устный счёт. 1 класс Сложение и вычитание смешанных чисел
Сложение и вычитание смешанных чисел Презентация по математике "Создание проблемных ситуаций на уроках математики" - скачать бесплатно
Презентация по математике "Создание проблемных ситуаций на уроках математики" - скачать бесплатно Тригонометрические функции
Тригонометрические функции  Презентация по математике "Математическая формула прекрасного" - скачать
Презентация по математике "Математическая формула прекрасного" - скачать  Понятие логарифма Изобретение логарифмов, сократив работу астронома, продлило ему жизнь. П.С. Лаплас
Понятие логарифма Изобретение логарифмов, сократив работу астронома, продлило ему жизнь. П.С. Лаплас  Методы решения логарифмических уравнений Субботина Наталья Аркадьевна Учитель математики МАОУ СОШ №1 им. М Аверина г. Валда
Методы решения логарифмических уравнений Субботина Наталья Аркадьевна Учитель математики МАОУ СОШ №1 им. М Аверина г. Валда Развивающие задачи для 5-6 классов Работу выполнила Исакова Ольга Андреевна, учитель математики МАОУ СОШ №35 с углубленным изуче
Развивающие задачи для 5-6 классов Работу выполнила Исакова Ольга Андреевна, учитель математики МАОУ СОШ №35 с углубленным изуче Матрицы и действия на ними
Матрицы и действия на ними Уравнения, сводящиеся к квадратным
Уравнения, сводящиеся к квадратным